[TOC]
基于遗传算法的 GRU 神经网络采油量预测
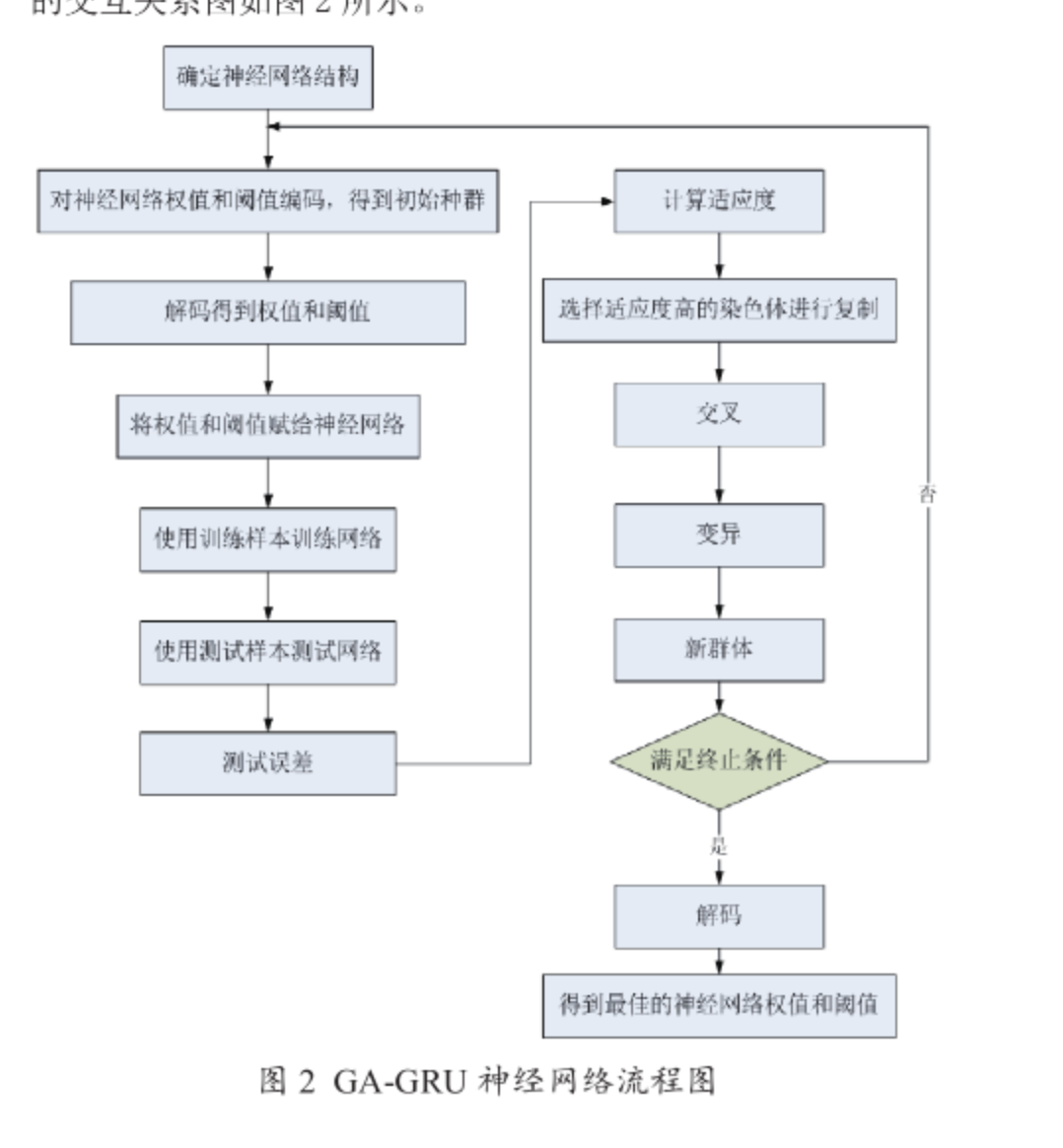
遗传算法中的全局搜索能力使得算法可以进行更好和更多的计算以得到神经网络模型中的最优的初始权重值以及阈值,使网络更快达到稳定的状态。
首先,根据待处理和预测的数据序列中包含的有关输入数据与相关输出信号的相关参数关系来具体确定该神经网络中的相关联接和架构参数以及每个连接的权值的个数和每个神经元阈值的个数等数值;其次,对计算这些相关联接中的神经元权值数目和各个神经元阈值数量都是使用到了实数的编码计算方式;
然后通过随机方法初始化输入连接的权重值及初始阈值并再利用前馈神经网络配置中出现的随机误差值作为对目标种群个体配置的自适应精度值并在最终时刻通过随机选择、交叉和变异的方法去寻找到匹配率最优值的目标种群个体,将优化配置完成后获得的初始输入连接的权值和初始阈值作为对目标神经网络配置的初始收敛状态值并最终对样本数据进行训练计算分析和预�测,以此达到加快了目标神经网络模型的初始收敛模型的收敛速度性和预测和计算过程的准确性。
最后,将遗传算法中所得出的最优个体值模型中神经元与其所对应神经元的连接量值和阈值分别赋权分配给其所对应连接的目标神经元,进行实现了一个实际而有效可行的目标神经网络模型的预测分析工作。
编码策略
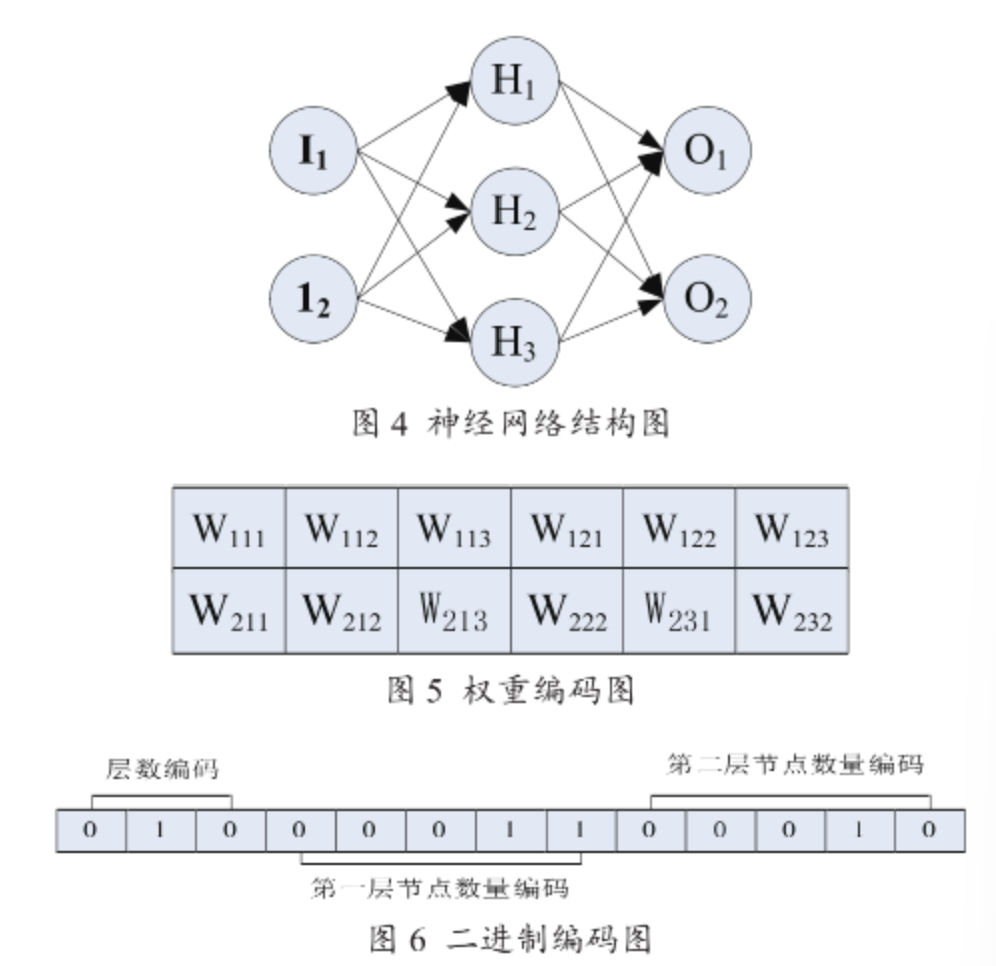
网络结构中的网络层数和每一层的节点数量、权重需要优化。对权重采用实数编码,对网络结构采用二进制编码。
常见的选择策略
常见的有:轮盘赌选择法、精英选择法。

使用遗传算法训练神经网络 (特别是 GAN)(百度)
(4 条消息) 有关神经网络和遗传算法? - 知乎 (zhihu.com)
GAN 是计算量特别大的模型之一,因为它相当于同时训练两个神经网络。
遗传算法可以利用两个好的神经网络的权值交叉,可以得到英国更好的神经网络。
工作原理
生成一组随机权重。这是第一个智能体的神经网络。对智能体执行一组测试。智能体收到基于测试的分数。重复此操作几次以创建种群。选择种群的前 10% 可以进行繁衍。从前 10% 中随机选择两个父母,他们的权重是交叉的。每次交叉发生时,都有��一个很小的突变机会:这是一个随机值,不在父对象的权重中。
随着智能体慢慢适应环境,此过程会慢慢优化智能体的性能。
优点
- 计算不密集
不需要进行线性代数计算。唯一需要的机器学习计算是通过神经网络前向传播。因此,与深层神经网络相比,需求非常广泛。
- 适应性强
人们可以调整和插入许多不同的测试和方法来操纵遗传算法的灵活性。人们可以在遗传算法中创建一个 GAN,方法是让智能体作为生成器网络,通过鉴别器进行测试。这是一个关键的好处,它使我相信遗传算法在未来的应用将更加广泛。
- 可以理解
对于普通神经网络,该算法的学习模式是神秘的。对于遗传算法来说,我们很容易理解为什么会发生一些事情:例如,当一个遗传算法被赋予 Tic-Tac-Toe 环境时,某些可识别的策略会慢慢发展。这是一个很大的好处,因为使用机器学习是为了使用技术来帮助我们深入了解重要问题。
缺点
- 需要很长的时间
- 不好的交叉和突变会对程序的准确性产生负面影响,从而使程序收敛速度减慢或达到某个损失阈值。
基于生成对抗网络 GAN 的人工智能临近预报方法研究
摘要
研究设计了基于生成对抗网络 ( Generative Adversarial Networks,GAN) 的人工智 能临近预报方法,并进行了业务试验。该方法利用广东 12 部 S 波段天气雷达 20152017 年海量雷达拼图资料进行人工智能学习来做临近预报。GAN 方法从一系列雷达 观测资料中,运用卷积法提取回波图像信息建立预报模型,并通过损失函数训练模型,得到基于人工智能技术的临近预报。对 2018 年发生在广东地区的 4 个天气过程的外 推预报试验表明,GAN 方法对对流天气过程的回波位置、形状及强度的临近预报多数 情况下与实况基本一致,具有较好的预报效果。但是该方法预报的回波范围偏大,对层 状云降水的预报效果较差。对西风带系统引起的降水,西南季风降水,东风系统引起的 降水以及台风降水的 18 个个例 1 h 预报的 3 个级别的回波强度检验发现,GAN 方法对 中等强度回波的预报较好,但对强回波的预报效果仍有待提高。
目前基于雷达的临近预报方法主要有交叉相关 法 ( 陈明轩等,2007) 、光流法 ( 曹春燕等,2015) 、粒 子滤波融合法 ( Chen et al.,2017) 等,这些方法通过 获取雷达回波运动矢量场来做临近预报。这些临预报方法主要基于雷达反射率单个因子,并没有考 虑风暴的动力学、热力学等因素对回波强度变化的 影响,因此这些传统的临近预报方法几乎没有能力预报回波的生消及强度变化,有必要发展新的临近预报方法。
模型优化
对基于雷达图像的临近预报,这个模型存在以 下两个问题:
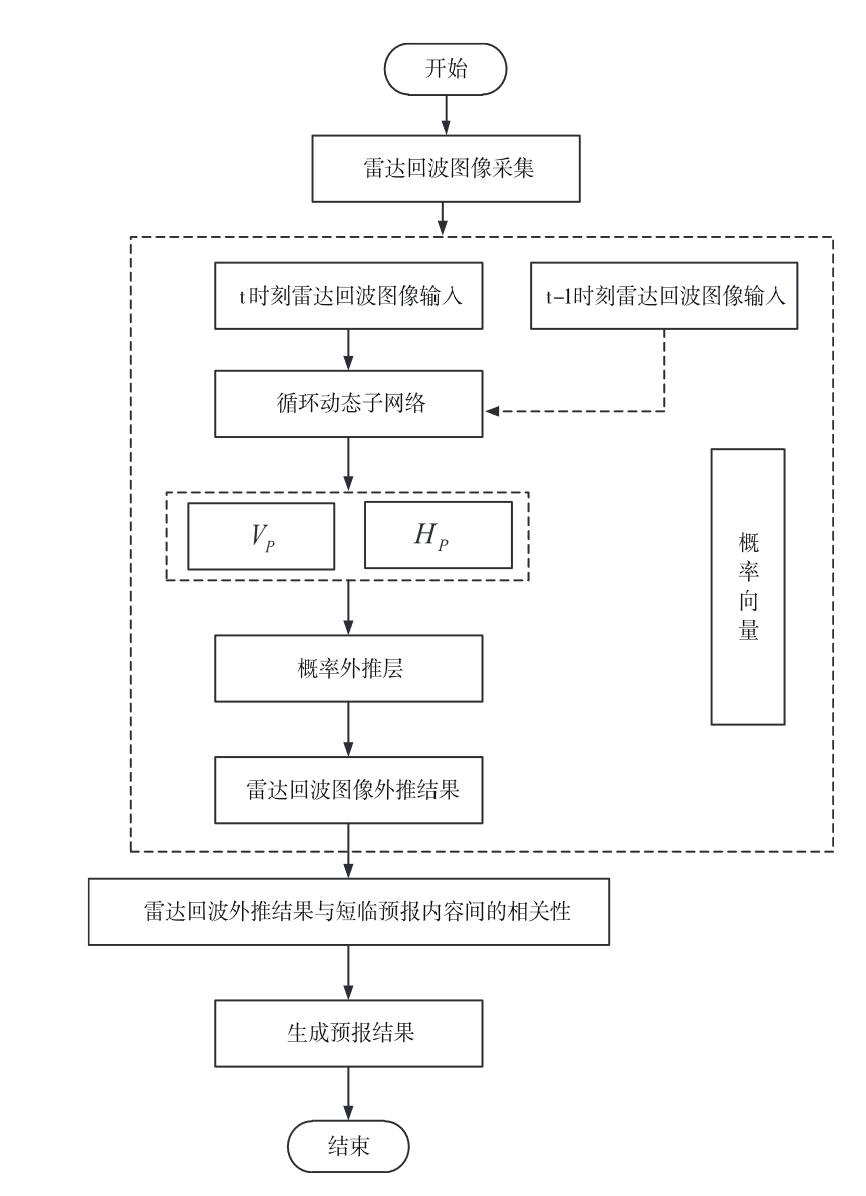
- 受卷积核影响,图像只能学习到较小范围的 空间相关性。建模的图像分类任务中可以通过加入 池化层 ( pooling) 缩小特征图,从而得到更大范围的 空间相关性。但因为池化层会导致特征图像尺寸压 缩,无法得到和输入图像序列一样大小的预测图像,所以图像预测不可采用这种方式。
- 对抗损失函数也会引起预测图像模糊,比如 目标像素点的概率分布存在两种可能 v1、v2,选择 ( v1 +v2) /2 有助于减小差分损失函数,但 ( v1 +v2 ) /2 这个数值出现的概率非常小。为解决问题,选择构造一个四级的图像金字。
陈元昭,等:基于生成对抗网络 GAN 的人工智能临近预报方法研究论著塔网络 ( 胡卫东,2017) ,将图像尺寸逐次缩小,即边 长逐次缩小为原始的 1 /2、1 /4、1 /8、1 /16,这样对于 相同的卷积核,可以获得更大的空间相关性。但缩 小后的图片会非常模糊,所以需要将缩小的图像经 过卷积后的特征图放大,与更大一级尺度图像拼接 再进行下一轮卷积 ( 图 2)
GAN
一个 GAN 方法框架,最少拥有两个组成部分,一个是生成器 G( Generator) ,一个是判别器 D( Discriminator) 。本研究中生成器 G 为预报模型,通过 学习真实图像分布让自身生成的图像更加逼真,以 骗过判别器。判别器则需要对接收的图片进行真假 判别。在训练过程中,会把生成器生成的样本信息 和真实样本信息传递给判别器 D。判别器 D 的目 标是尽可能正确地识别出真实样本,和尽可能正确 地剔除生成的假样本。
loss
为解决预报模型的可用性问题,对构建的 GAN 模型采用两个损失函数进行协同优化训练。将生成 器 G 产生的损失函数,判别器 D 的损失函数等两种 损失函数对模型进行共同优化训练。原始的 GAN 方法模型使用随机噪声作为输入 初始值,完全依赖对抗损失函数进行模型优化,计算量很大。对于临近预报的雷达图像预测问题,需要输入预测时刻向前的多个时次、多个高度层的图像。这些输入的雷达图像也可以理解为一张图像的多个通道,对目标时刻的雷达回波在获取了相应特征后 进行预测,并采用如下对抗损失函数对判别器 D 进行优化。
人工智能在短临降水预报中应用研究综述
背景
利用气象数据实现对短临降水的预测是国内防灾减灾的热点和难点。
短临降水量预报的目标是在未来 (0-6h) 内,对当地区域的降雨强度进行预测,具有准确性、实时性、大规模的特性。由于天气��事件本身是一个随机事件,加上降水受气候带的、大气环流、地理高度、季节的等多重因素的影响,所以短临降水具有高度非线性的复杂特征,因此需要高时空分辨率和高时效性的数据来训练模型。
使用雷达图进行短临降水预测主要是通过雷达回波外推实现的。雷达回波外推图既包括时序信息,又包含空间信息,从而使用雷达数据进行降水预测可以看作时空序列预测问题。
传统方法
- 物理统计方法
该方法通过收集与降水相关的多种关联因子,并利用数据建立物理统计模型,从而对长期的降水量进行预测。所选择的因子具有一定的物理意义,利用前兆信息因子和后期信息的遥相关原理,对降水的轻重程度进行划分。
- 马尔可夫链预测模型
Markov 过程是研究某一事件的状态及状态之间转移规律的随机过程,状态转移概率只与上一步转移后的状态有关,而与之前所有状态无关,即上一步的状态保存了之前所有的状态信息。马尔可夫链是时间和状态都离散的 Markov 过程,可以根据 n 时刻的状态预测 n+1 时刻的状态,概率最大的值即为预测结果。
- 数值天气预报方法
数值天气预报 (numerical weather prediction) 是根据大气实际情况,在一定初值和边值条件下,通过用数值方法求解支配大气运动的流体动力学和热力学方程组,来预报未来的大气环流形势和天气的。它具有数字化和定量客观的特点。
基于雷达图的预测方法
- Z-R 关系式法
通过雷达回波强度和雨强二者之间建立的关系式来估算,即天气雷达反射率因子 (Z) 和雨强 (R) 的 Z- R 的关系式 Z=aR, a 和 b 为经验系数
- 降水云团外推技术
首先获取雷达反射率图像,然后根据云团外推算法进行云团外推。云团的外推指的是根据相邻时刻同一云团形成的两幅反射率因子图,计算它们之间的变化,并依此得到未来短期时刻的云团形态
- 光流法
1950 年,Gibson 首次提出光流的概念。光流法是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法。使用光流法有着 3 个前提假设:
-
亮度恒定不变,即同一目标在不同帧间运动时,亮度不会发生变化;
-
时间连续或运动是微小的,即时间的变化不会引起目标位置的剧烈变化,相邻帧间位移小;
-
同一子图像中像素点具有相同的运动。 光流法善于观察图像的变化,并利用相邻图像间的相关性获取运动信息,对其实现追踪。这与利用雷达数据对云团进行识别追踪进而完成降水预测的思想相一致。
未来的发展
首先,进一�步提升短期降水预报准确率可以考虑 2 个研究方向:
-
将人工智能技术与传统数值预报模型结合,理论驱动与数据驱动互为补充,联合开展人工智能技术,利用多种数值预报产品及实况观测资料,针对不同季节,开展人工智能技术在中短期降水预报中的偏差订正研究,建立分时效降水偏差订正预报模型,生成中短期降水预报产品,提升中短期降水预报准确率;
-
将降水预测问题看作是一个图像的转换问题,开展 2 ~ 6 h 雷达外推与模式融合降水预报等技术应用研究,使用人工智能技术提高雷达外推的准确率和及时性。
对于强天气预警技术,采用基于大数据和人工智能的强降水、雷暴大风、冰雹、龙卷风、雷电等强对流天气系统监测识别、分类强对流天气智能识别和智能报警技术,建立强天气智慧预报预警业务;
机器学习在强对流监测预报中的应用进展
强 对 流 天 气 预 报 主 要 关 注 时 空 尺 度 较 小、发 展剧 烈 的 天气现 象,如 冰 雹、雷 暴 大 风、短 时 强 降 水、龙卷 等 恶 劣 天 气。
传统方法
传 统 的 客 观 做 法,根 据 物 理 机 理、预 报 员 经 验 和统 计 结 果,通 过 对 观 测 数 据 设 置一定 阈 值,对 强 对 流天 气 进 行 识 别 和 监 测,通 常 会造 成 虚 警 率 偏 高 (外推法)。
冰雹和雷暴大风往 往 在 局 地 性 极 强 的 对 流 性 系统 中 发 展 而 来,由 于 局 地 性 很 强,现 有 观 测 网 依 然 难以 完 全 捕 捉 ( 郑 永 光 等,2 0 1 7) , 具 有 很 大 的 观 测 难度。
风暴的识别与追踪
基于 卫 星、雷 达、闪 电 等 观 测 数 据,利 用 机 器 学习 算 法,能 够 有 效 实 现 对 对 流 系 统 的 识 别 和 追 踪,提取 对 流 系 ��统 的 移 动 方 向、移 动 速 度 等 信 息,为 对 流 预警 提 供 重 要 信 息。
结论
机器 学 习 在 大 气 科 学 领 域的 应 用 基 础 仍然 依 赖 于 高质 量 的 观 测 数 据、可 靠 的 数 值 模 式 预 报 结 果 以 及 深刻 的 天 气 原 理 认 识,且 要 根 据 不 同 的 应 用 场 景 结 合物 理 机 理 选 择 合 适 的 机 器 学 习 方 法。究 其 本 质,机器 学 习 只 是一个工具,并 不 能 替 代 基 础 天 气 观 测 数据、数 值 预 报 模 式、天 气 学 和 大 气 动 力 学 基 础 理 论 发展的 研 究。在 利 用 人 工智 能 技 术 发 展 天 气 预 报 技 术的 同 时,也 需 时 刻 牢 记 大 气 科 学 基 础 理 论 才 是 强 对流 天 气 预 报 的 基 础 和 土壤。
基于深度卷积神经网络的强对流天气预报方法研究
多源观测数据综合应用,能够有效取长补短。虽然静止气象卫星具备对流初生的观测能力,然而其观测的主要是对流云顶的发生发展特征, 尚无法实现对流系统内部的观测。天气雷达则可观测对流风暴的内部分布特征,能够与静止气象,卫星数据形成互补,实现对流系统的多方面观测。但多源观测数据表现形式、物理意义各异,如何将多源数据实现有效融合,也是当前面临的挑战之一。机器学习算法能够自动学习并提取特征,为多源数据融合提供了新的思路。
基于 MSG 卫星的成像仪 SEVIRI 探测的云顶顶高、云顶温度、云相态和云水路径等因子,Kühnlein et al(2014) 利用随机森林、Meyer et al(2015) 利用四种机器学习算法 (RF、神经网络、平均神经网络和 SVM) 进行定量降水估计。他们首先区分降水区与非降水区,然后实现对流降水与非对流降水区域划分,�最后不同的降水区域使用不同的降水反演因子,实现中纬度地区全天候的定量降水估计。
基于数值预报的强对流天气短期分类预报
中国地域辽阔、地势复杂,不同地区地形条件、气候条件差异显著,强对流天气发生发展条件与特征阈值范围必然会存在差异,难以使用一套统一的特征物理量阈值组合来实现全国分类强对流天气的预报。
强对流天气系统时空尺度较小,具有复杂的物理过程与动力特征。随着中小尺度观测网络的日益健全,观测手段的日益丰富,观测数据迅速增长。如何有效地从每一次强对流天气的过程中学习强对流过程的发生发展机制,如何从大量的数值模式数据中提取各类强对流天气的特征参量和阈值范围,如何综合考虑**每一个地区的地理、气候环境,**成为能否有效预报强对流的关键。深度学习算法能从大量数据中自动提取特征,深入挖掘有效信息,并综合考虑各地地理环境与气候差异,将有效改善强对流预报结果。
浅析短临预报在农业防灾减灾中的作用
农业防灾减灾中的难题为强对流天气预报,此类灾害不仅生命史比较短,而且突发性很强,部分灾害仅几分钟或者几十分钟,最长不超过十几个小时。
以往农业防灾减灾实践中采取的短期预报,仅能预报 13 d 的天气,若想提前 12 h 了解天气变化,精准掌握气象动态,还需要依靠短临预报,更加准确地捕捉所在位置,精准捕捉强对流天气系统的变化轨迹,做到精准预报降雨区域,准确预判未来数小时内是否会产生洪涝灾害,通知居民撤退,指导防灾减灾工作的开展与落实。
气象部门还要做好灾情的收集以及上报,针对给本地区造成重大灾害的天气或者关键性天气过程进行系统化总结, 评估效益,提出具体的应对措施;结合卫星云图以及雷达资料等,做好实际数据资料的分析,利用现代化技术手段实现对天气的紧密监视,如果发现变化情况,则必须及时通知农业部门等相关部门做好防灾减灾工作,及时在本部门微信、微博、抖音、知天气 app 及农气宝 app 等各类线上软件平台做好发布工作;短临预报工作人员要积极学习新知识与新方法,高质量落实预报服务工作,为农业防灾减灾措施的高质量落实提供帮助。
一种雷达回波外推短临预报方法仿真
动态神经网络
随着全球气候恶化情况的逐渐严峻,各种突发性、极端天气 越来越多见,这类气象具有破坏性较大,影响范围大等特点,对人们日常出行,农作物生产以及施工建设等均会造成一定 程度的影响。因此,需要对短时突发天气进行准确预报。
当前普遍使用的雷达回波外推技术多以深度学习和卷积神经网络为基础 ,但由于自然环境的多变,导致短临预报结果具有一定误差,且时效性较差。针对上述 问题,考虑外推图像与输入图像间的高度相关性,提出基于循环动态卷积的雷达回波外推短临预报方法,提升卷积神 经网络对于时序图像的处理效果。
循环动态卷积神经网络以动态卷积神经 网络为基础 ,引入循环神经网络,利用其构建相邻时刻输 入图像序列间的相关性,以此提升具有时序特征输入图像的 外推结果精度。
基于深度学习的雷达降水临近预报研究
数值天气 预报在不同时空尺度上都有较强的预报能力,但在预报时存在较为严重的公式化,在一定程度上限制了预报的精度;同时也存在预报延迟,短时临近预报能力弱,模式偏差随着预报时间的增长愈发显著等问题,不能满足临近预报的时效要求。
数值天气 预报在不同时空尺度上都有较强的预报能力,但在预报时存在较为严重的公式化,在一定程度上限制了预报的精度;同时也存在预报延迟,短时临近预报能力弱,模式偏差随着预报时间的增长愈发显著等问题,不能满足临近预报的时效要求。
临近预报主要是根据基于当前时刻的探测资料,对后续 0-2h 内的天气过程 进行预报分析的高时空分辨率的天气预报。从监测手段来看,目前主要应用的方法有遥感卫星观测、数值预报法和基于雷达回波的外推法。
因为光流法具有一定的物理意义,使得它对演变速度较快的强对流天气过程 中的预报效果相对较好。
展望
基于雷达资料的临近降水预报方法是气象预报研究的热点,天气雷达资料具 有数据量大、规律性强的特点,因此利用深度学习模型学习天气系统变化特征和 规律具有较大的研究价值。
论文主要内容
利用不同的采样方法对新一代多普勒天气雷达回波数据进行采样,构造雷达 回波数据集;构建了 ConvGRU 与 ConvLSTM 深度学习预报模型,利用 20182019 年 4 月 -9 月雷达回波数据,分析雷达回波变化规律,引入验证集验证模型 精度;利用 2019 年 6-7 月的雷达及雨量计数据,进一步通过𝑍 − 𝑅关系反演站点雨强。通过与传统方法进行对比验证,深度学习模型在临近降水预报种取得了较 好的实验结果。主要研究结论:
- (1) 对于选取 3000m 高度层的单层数据和对 3000m-5500m 范围内的多层 数据进行采样的两种数据处理方式,单层数据中所��包含的信息较少,只含有当前 高度层的回波状态,多层的采样数据则反应了更多的天气状况,但回波中的峰值 相较与 3000m 高度层偏低;在回波预测的评价指标中,总体变化趋势大致相同,但多层数据的各项指标都相对偏高,误报率的值也相对较高,在降水预报业务的 实际应用中会存在更多的误差。
- (2) 对比预测回波的形状,ConvGRU 与 ConvLSTM、LSTM 和 Of 四种方 法中,ConvGRU 与 ConvLSTM 的效果都相对较好,在较长时间的预测中 ConvGRU 更加具有优势;对比四种方法的预测评价,ConvGRU 与 ConvLSTM 的各项指标都呈现较高的精度,Of 在 1h 内的预报能力较好,LSTM 整体精度偏低。
- (3) 在雷达回波预测中引入阈值来检验,不同强度的雷达回波预报的评分,随着雷达回波强度的增加,CSI 评分呈下降趋势,整体预报精度降低。对 30dBz 以上的回波预报效果不佳,成功率低。
- (4) 对站点的降雨强度进行估测,ConvGRU 和 ConvLSTM 总体离散度较小,稳定性高,误差均相对较低;Of 虽然相关性不错,但低估程度明显;而 LSTM 的估测精度普遍偏低,不能较好的估测站点的雨强
- (5) 深度学习模型解决非线性问题的能力较强,在业务应用种具有较好的 推广能力,大量数据的学习能够从复杂的时间、空间序列中找出一定的演变规律,在相似的降水过程中做出快速反应,从而进行高精度的预报。
四种机器深度学习算法对武汉地区雷达回波临近预报的检验和评估
简述
基于 PredRNN++ 、MIM、CrevNet 和 PhyDNet 四种机器深度学习算 法。
均 方 误 差 (MSE)、结构相似性指数 (SSIM) 、命中率 (POD) 、虚警率 (FAR) 和临界成功指数 (CSI) 等指标检验评估了四种机器学习算法对武汉地区雷达回波��临近预报的预报性能。
得到 以 下 主 要 结 论:MIM 算法的 MSE 和 FAR 最低,SSIM 最高;PredRNN++算法的 POD 和 CSI 最高。机器深度学习算法的 POD、CSI 和 SSIM 均高于光流法、FAR 和 MSE 则更低、其 中 SSIM、POD、CSI 三种指标的提 升幅度在 3.2% ~24.7% ,MSE 和 FAR 两种指标的降幅在 13.1% ~ 43.3% ,30min 以 内,除 CrevNet 外,其余三种机器学习算法和光流法的预报能力较为接近;30min 以后,深度学习算法和光流法都随着预报时效的延长 ,预报能力均显著下降,但机器学习算法下降得更缓慢,尤 其 是 60min 以后光流法的降幅进一步增加,显示出机器学习长预报时效的优势。
四个不同回波形态、不同发展趋势个例的分析结果表明,机器学习算法不仅具备对一定回波强度变化的预报 能力,而且对回波强度和面积变化趋势的时间节点预报也与实况基本一致。此外,机器学习算法对回波运动的预报能力明显强于光流法,显示出机器学习算法良好的应用前景。
临近预报的方法主要有雷达回波外推预报、中尺度数值模 式预报以及概念模型预报等 (Wilson e t. al ,1998)。中尺度数值模式预报由于模式初始场协调和资料同化时效等问题的限制,在最初的几个小时内其预报效果较差,甚至无法直接用于临近预报 (王丹等,2014;吴 剑 坤 等,2019);概念模型预报带 预报员一定的个人主观性,且精细化程度较低。
雷达资料
雷达回波数据进行了孤立噪音过滤和超折射回波抑制 (吴涛等,2013),并利用中值滤波 (赵 悦 等,2007) 进 行质 量 控 制。
检验方法(为统一有效地评估哥算法的预报能力)
以实况回波图像为基础,将实际回波图像和预报的回波图像格点化成单独的像素点,再逐个像素点检验预报准确率,用均方误差 (MSE),用结构相似性指数 (SSIM) 衡量预报回波图像与实际回波图像的相似度,SSIM 介于 -1~1,当两张图片一模一样时 SSIM 的值等于 1。MSE 和 SSIM 的计算公式如下:
为了考察各方法对不同量级范围内反射率因子的预报能力,采用临界成功指数 (critical success index,CSI)、命中率 (probability of detection,POD) 和虚警率 (false alarm rate,FAR) 等指标对预报结果进行量化评估,其计算公式如下:
| 实况 | 预报 | 预报 |
|---|---|---|
| 实况 | >=k | < k |
| >=k | NAk | NCk |
| < k | NBk | NDk |
四个机器学习算法介绍
-
PredRNN++算法
在 ConvLSTM 算法的基础上,将可以记忆的单元放置在算法的堆叠结构中,提出了 PredRNN 算法,为了缓解该算法中梯度容易消失的问题以及提高其对短时非线性时空特征的提取能力,引入了 GHU(gradient highway unit),该结构使得梯度能够在第一层和第二层之间高速传递,有效抑制了梯度的消失,最终提出了 PredRNN++算法。
-
MIM 算法
该算法分两次对图片信息进行提取,首先由 MIM-N 结构提取出平稳信息,而后传递给 MIM-S,MIM-S 则利用门控来选择记忆或忘记非平稳信息的多少,同时通过多层模块之间相互的差分运算,使得非平稳信息缓慢降低,从而提取出各种高阶的非平稳信息,最终将所提取的平稳信息和非平稳信息相结合,进行输出和预测。
-
CrevNet 算法
该算法是一种全新的嵌套了三维卷积模块的双向可逆自编码结构,其在一系列正向和反向计算过程中使得输入和特征之间建立了一对一的双向映射关系,这种关系理论上保证了在特征提取过程中不丢失信息,因而保留更多信息进行预测,明显提高了预测图片的清晰度。
-
PhyDNet 算法
该算法参考了 MIM 算法的基本假设,将图片信息分为已知的物理过程和未知因素(包括生消、发展等两个部分),然后用深度网络结构来约束模型,以ConvLSTM 为主要内核来提取未知因素,此外利用卷积过程模拟偏导,从而学习到新的物理信息,最后将物理信息和已有的未知因素结合,从而进行更好的预测。
结论
虽然机器深度学习算法较光流法表现出一定程度的优势,但也存在一些问题:首先,从时间演变来看,机器学习算法预测的回波 在 60mm 之 后 逐 渐 开始“雾化” ,这 种“模 糊化”作 用 会 让小 面 积 的最强回波被 平 滑 掉,并“泛 化”出较大的 次 强回 波的 范 围,因此在业务应用过程中,对 于 60min 后,尤其是 90mm 后,机器学习预报出回波面积显著增大的区域,需 要特别警惕降水区 域 可能有显著的变化
基于 ConvLSTM 的广西短临降水预报
数据预处理
雷达波束在传播过程中遇到山体、植被和建筑物等地干扰,导致雷达发射的电磁波束受到局部或全部遮挡。地物干扰会导致观测信号出现噪声,这些会对真实雷达回波运动矢量分析和降水估计带来一定误差。(采用局部均值算法进行地物杂波去噪)
评估方法
在计算上述指标时,首先需要设定一个回波强度阈值,在实际观测中,若某个 像素点的值大于回波强度阈值,则判定判定实际观测值是活跃的,否则为不活跃;若回波外推结果中的某个像素点的值大于该回波强度阈值,则判定预测值为活跃,否则为不活跃。对于实际观测值和预报值均为活跃的情况,认定为预报成功,记为 S;对于观测值为活跃而预测值为不活跃的情况,视为漏报,记为 M;对于实际观测值为�不活跃,预报值为活跃的情况,视为空报,记为 F。
基于卷积神经网络的逐时降水预报订正方法研究
目前 DL 在气象领域的应用思路仍然集中在如何根据实况观测资料推测预报对象未来的演变过程,DL 与数值预报的融合应用之先例相比甚少。能否在快速更新同化预报系统对未来几个小时的环流形势和环境条件预测的基础上进一步通过 DL“推 导”出相应的降水状况,是具有研究价值和实践意义的问题,亦是本文的研究重点。
天气演变过程本质上仍是物理演变过程,任何尺度上的物理机制都必须受到物理定律的约束,这正是 DL 所不擅长的。
数据预处理
图像矩阵在输人模型之前需要进行标准化或归一化处理,物理量数据包含各种不同量纲的物理量,所以同样需要类似的预处理。但物理数据不同于图像像素值存在着明确的上下限,而且不仅物理数据的空间分布是关键信息,其数值的相对高低对模型输出亦有至关重要的影响。为了较好地保留物理量场的空间分布以及数值区间的信息,采用先标准化后缩放计算的预处理方案:先计算出每种物理量场的空间平均值 M,再对均值序列进行标准化处理,将标准化值与原先的空间平均值 M 之比作为缩放系数,最后将每个原始样本与对应的缩放系数相乘 即得到比较合适的新样本数据。即对于每个样本中的物理量矩阵 X 作如下变换:
基于深度学习和雷达观测的降水短临预报研究
短期降水预报是气象服务领域的一个重要问题,根据世界气象组织 (WMO)1985 年的定 义,临近预报是基于目前的天气情况进行 0~2h 的降水预报,但建立一个有效的短期降水预 报系统是研究人员面临的最大挑战之一。首先,由于云和降水具有十分复杂非线性的过程,它涉及水循环中的地表与天空之前的水分、热量、动量等交换,有云不一定能形成降水,需要水汽分子在云滴表面凝聚,通过这些大小不等的云滴不断的分裂与合并,当云滴增大 到可以克服空气阻力和上升气流,并且在降落到地面之前不被蒸发才会形成降水。因此,它的主要形成条件需要充足的水汽,气块抬升并冷却凝结,较多的凝结核。降雨一般可以 分为,锋面雨,对流雨,地形雨,气旋雨。强对流天气发生于中小尺度天气系统,强对流 天气的发展具有一定的空间性,同时强对流天气具有自身的特点,速度快、空间比较小,因此对其进行预报进行一定的难度。
随着观测技术的提升,各种各样气象数据开始不断增长,已经发展成了气象大数据 [3],为了处理庞大的数据,通过使用人工智能和机器学习等方法,可以有效的学习其中的时空 特征。基于机器学习的降水短时方法相对传统的预报方法,能够更好的处理降水这种非线 性的连续过程,进而提升降水预报的精准度。然而降水过程变化复杂存在很多的不确定性,因此为了提高降水预报的准确度,需要系统的分析深度学习的方法和雷达观测在预报能力。
基于智能计算的广西大风短临预报预警系统的产品检验
利用机器学习和人工智能技术研发了广西大风短临预报预警系统,该系统的产品与同期广西各地气象局 发布的大风预警信号 (以下简称“人工预警”) 进行比较分析。结果表明:(1) 按业务评分规定,大风预警系统在漏报率 和命中率方面更优,人工预警在 TS 评分和空报率方面更优;(2) 有效提前预警情况下,大风预警系统在大风蓝 色、黄 色预警和不分级预警中 TS 评分较高。基于对大风预警系统和人工预警的数量、TS 评分和预警提前量的差异分析,广 西大风短临预报预警系统的产品性能达到同期人工预警水平
基于机器学习的短临预报方法及其在空气质量保障中的应用
基于多个数值模式 ( NAQPMS、CMAQ) 预报结果和站点观测资料,采用岭回归机器学习方法构建了一种多污染物 短临预报方法。
短临预报表现出很好的预报能力,可以有效改进数值模式的预报趋势和量值。从日均 模拟效果来看,短临预报的颗粒物相关系数达到 0. 9 以上,均方根误差小于 5 μg / m^3,而且预报的臭氧相关系数和均方根 误差分别为 0. 99 和 2 μg / m3。相较于日均数值模式预报结果,短临预报可使颗粒物和臭氧的预报相关系数至少提升 16% 和 9%,预报均方根误差至少下降 50% 和 86%。对于小时模拟效果,短临预报能够更好地把握颗粒物的小时变化特 征,其相关系数较模式提升了 0. 2 以上; 同时短临预报能够更好地再现观测到的臭氧日循环特征,对白天的峰值和夜晚 的低值预报更好,其相关系数高达 0. 9。
MetNet: A Neural Weather Model for Precipitation Forecasting
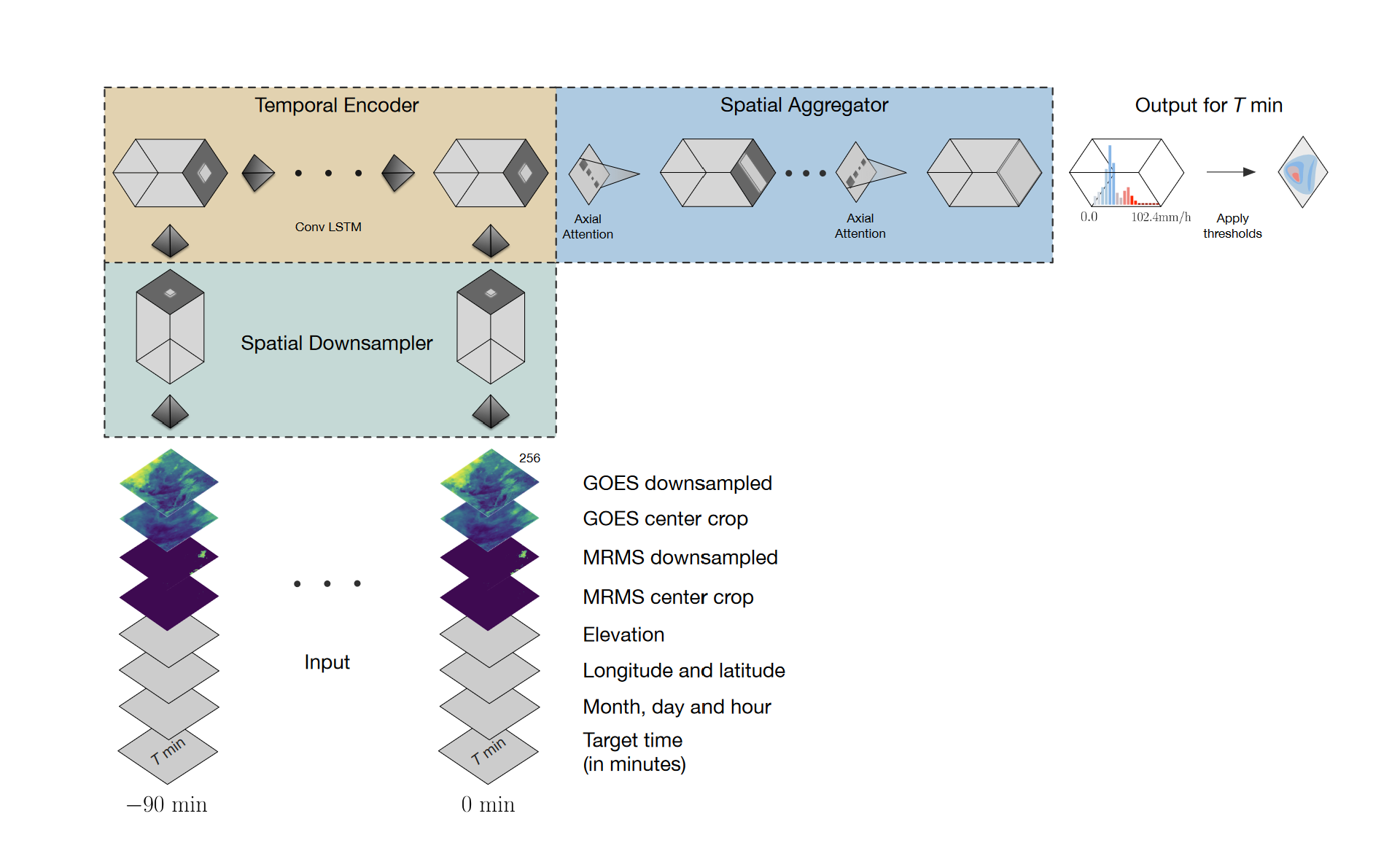
- Spatial Downsampler 空间下采样器
- Temporal Encoder 时间编码器
- Spatial Aggregator 空间聚合器
Deep learning and process understanding for data-driven Earth system science
摘要
机器学习方法越来越多地用于日益增长的地理空间数据流中提取相应的模型特征和深入特点,但是目前的方法在系统行为受制于时空背景时还不能得到最优的方案。在这里,主要目的并不是改进经典的机器学习算法,我们主张这些背景线索应该成为深度学习一部分 (一种可以自动提取时空特征的方法) 来更深地获取地球科学领域难题的过程理解,提升季节预报或者多时间尺度长距空间相关模拟的可预报能力,譬如,下一步将建立混合模型方法,将物理过程模式与数据驱动型机器学习的通用性耦合起来。
巨大的数据量在处理起来充满了挑战,其统计特性里包含了大量的不确定性。地球科学领域海量的数据也具备大数据四大特征:volume, velocity, variety and veracity(体积,速度,多样性和准确性),例如各种遥感、定点观测、模式数据。如今面临挑战就是如何从这些大数据中提取并解读信息,因为信息收集速度远大于人们所能消化的速度。数据的增多并未带对系统预测能力的提高,科学家需要对数据进行理解。在这种背景下,机器学习就是一种极佳的选择。
对于地球科学领域的科学家在未来面临的不可回避问题就是:
1.提取海量激增数据中的有用信息;
2.遵循相关的物理定律前提下,相比于传统的同化方法能够从数值模式中获取更多有效特征。
(1)**地学中最先进的机器学习。**诸如神经网络、随机森林方法很早就应用于地学中的分类、变化检测、土壤制图问题。但这些应用是针对空间,在时间上是相对静态的,但地球是不断变化的。机器学习回归方法在时间动态上具有优势,比如具有隐含层的人工�神经网络,可预测碳通量在时间与空间上的变化。但这些应用也存在一些问题需要注意,比如外推能力,抽样或数据偏见,忽视混杂因素,统计关联与因果关系等。经典的机器学习方法需要一些先验知识确定一些时空相关 feature,而不能自动探索数据的时空特征。一些时空动态特征比如“记忆效应”可以作为 feature 手动加入到传统机器学习中,但最新的深度学习已经没有这些限制。
(2)**深度学习在地球系统科学中的机遇。**深度学习已在其他领域得到了众多应用,但在地学中的应用还处于初级阶段。已有一些研究显示深度学习可以很好的提取时空特征,比如极端天气,而不需要很多人类干预。这也可用于城市变化的遥感自动提取。深度学习方法通常被划分为空间学习 (例如,用于对象分类的卷积神经网络) 和序列学习 (例如,语音识别),但两者逐渐融合,可应用视频与动作识别问题。这些问题类似于地学中随时间变化的多维度结构,例如有序降水对流与植被状态。虽然有很大应用前景,但应用于时空变化的大气海洋传输或植被动态还有待发展。
(3)**深度学习在地球系统科学中的挑战。**虽然传统深度学习的应用对象与地学现象有很大相似性,但也存在重要区别。比如高光谱、多波段就比基于三原色 RGB 的计算机图像识别复杂很多,此外还有带噪音、有缺测的卫星数据。另外,波段、时间与空间维度的集合也会带来计算量的挑战。计算机图片中识别可大量“狗”,“猫”现成训练样本,而地学中没有类似被标记的大量训练样本,如干旱。对外,作者总结出五大挑战,分别来自可解释性、物理一致性、数据的复杂与确定性、缺少标记样本、以及计算需求。若这些挑战能解决,那么深度学习将对地学带来巨大改变。近期最有前景的应用是”临近预报“(nowcasting),未来是长期预测。作者认为深度学习将很快成为地学中分类与时空预测问题的主要方法。
(4) **与物理建模集成。**物理建模 (理论驱动) 与机器学习建模 (数据驱动) 过去往往被认为是两个领域,具有不同范式。但其实两种方法可以相互补充的,前者外推能力强,后者更灵活可发现新规律。作者提出二种方法可结合的几个潜在点:改善参数化、用机器学习“替代”物理模型中子模块、模型与观测的不匹配分析,约束子模型、代替模型或仿真。
(5)**推动科学发展。**机器学习方法无疑给分类和预测问题带来大幅提高。机器学习的数据驱动方法还可从数据中挖掘出过去不知道的新信息,从而推动新机制新认识的产生。
(6)**文章结语。**地球科学大数据时代机器学习很有用,但也存在应用挑战,作者对此提出四点建议:识别数据的特殊性、推论的合理性和可解释性、不确定性估计、针对复杂物理模式进行验证。未来过程模型与机器学习将进一步结合。数据驱动的机器学习不会替代物理模型,但是会起到补充和丰富的作用,最终实现混合建模。
深度学习模型 TAGAN 在强对流回波临近预报中的应用
摘要 近年来深度学习模型在解决对防灾减灾影响巨大且极具挑战性的临近预报问题的应用逐渐多。本文基于对抗神经网络 (GAN) 优化构建 TAGAN 深度学习模型预测未来 1 个小时的雷达回波图像。并且鱼 Rover 光流法、基于卷积神经网络的 3D U-Net 模型进行对比实验。检验表明 TAGAN 要优于传统的光流法和对比的 3D U-Net 深度学习模型,在命中率 (POD)、虚警率 (FAR)、临界成功指数 (CSI) 以及相关系数等多种评分上。
本文模型输入 采用 前几帧的雷达图像 + 各自的光流图
大部分深度学习模型结构主要基于 RNN 和卷积神经网络 (CNN),受限于卷积核的大小,普通的卷积层只能提取到有限范围且固定的信息,对于范围较大的的系统性回波刻画能力往往受到限制。
对于 RNN 模型,预测的效果往往随时间变差,一方面由于大气的混沌和高度非线性难以预测,另一方面 RNN 的预测依赖于上时间步的输出,误差将不断累计。
另一方面,尽管光流法对系统生消以及失效有其局限性但其对已知时刻的回波系统的位置变化以及运行特征有较强的刻画能力,因此能否在深度模型编码阶段 (预报因子构建) 融入光流法刻画信息。
TAGAN 模型介绍
卷积层一方面用来对数据进行上下采样,从而让模型训练的显存控制在可以接受的范围之内,另一方面可以提取到回波数据的低维到高维的数据信息。
模型内部的卷积层均有 2D 卷积层,批量归一化层、LeakklyReLU(负斜率设置为 0.2) 激活函数组成。
生成器的目的是生成更为真实的雷达回波序列从而骗过判别器,
判别器的目的是尽可能的区分出来自生成器和来自真实雷达的回波序列。
模型输入为 前几帧的雷达图像 + 各自的光流图。回波序列图和光流图分别经过对应的卷积层 (第一层) 进行特征融合,之后数据经过卷积层下采样通过注意力机制模块进入 ConvGRU 单元,在训练的过程中尝试了在卷积层中加入若干残差块,提高卷积层的提取信息的能力。
模块中原特征图经过三个 1X1 的卷积后分别得到三个特征图,通过前两个特征图计算出 attention 权重系数在与 第三个特征图��作矩阵乘法运算得到注意力特征图,最后讲注意力特征图与原特征图相加得到任意位置的依赖关系。
自注意力模块计算开销比较大
模型输出:
最终解码端将会输出 10 帧预测的回波图像,接着预测的回波图像和真实回波数据分别交替输入判别器进行训练。
判别器反向传播的梯度也会进入到生成器 (编码结构) 中帮助生成器有更好的预测,
理想的判别器输出概率为 0.5,即生成器生成的回波数据达到了以假乱真的效果,使得判别器不能以较大的概率判定器是真是假,生成器和判别器达到纳什平衡。
损失函数:
在雷达回波预测的任务中,常用的损失函数有平均平方误差 (MSE) 和平均绝对误差 (MAE),但这俩个损失函数容易造成预测图像的模糊化,未来更好的生成图像和更精确的预测还引入图像梯度差损失函数 (GDL) 和结构相似性损失函数 (SSIM)。
GAN 不同的损失函数和训练方式,发现对抗损失的权重系数对训练结果至关重要,单独只使用对抗损失函数训练是非常容易导致训练的失败,需要模型训练初期以 MSE 与 MAE 损失函数为主导的损失函数,然后再将对抗损失函数作为主导损失函数进行��训练。
结果:
TAGAN 和 3D U-Net 这两种深度学习方法的清晰度均弱于光流法,主要是由于深度学习模型预测过程中使用了平均平方误差 (MSE) 和平均绝对误差 (MAE),这两个损失函数较容易造成预测图像的模糊化且图像模糊的情况随着时间增加,他们更趋向一个“平均”的效果。
而且在使用 MSE 损失函数的时候假设数据是高斯分布的,但子啊梯度反传的时候,损失函数计算的是拼接在一起的序列预测值与真实序列值,于是对空间上出现的不连续回波区和时间上的旋转和耗散拟合不够,导致训练的结果是在总体上的距离与真实缝补相近,因此预测的结果就会出现直观上的一个“平均”现象。
==》所以有必要同时结合 MAE、MSE 和对抗损失进行模型构建
(可以在训练初期给 MAE、MSE 一个较大的权重,后面给一个较小的权重)
现在深度学习方法在雷达回波预测还存在的问题:
- 雷达回波的数据不够,
- 预测图像模糊,
- 预测效果随时间的变差。
基于时空预测网络和卷积神经网络的短临降水预测研究
短临存在的问题和不足
- 已有的时空预测网络,大多针对的是视频这种时间分辨率较高的时空序列,而 雷达数据间隔时间较长,加上气象系统本身的复杂性,雷达回波序列预测更加困难,尤 其是对流的产生和消失不能做到很好的预测
- 在数据的利用方面,没有充分地利用雷达数据的时空特性,导致预报的准确率 不高。除此之外,雷达数据质量层次不齐,没有进行有效的质量控制,这也是导致预报 准确率不高的一个原因
RadarNet 模型
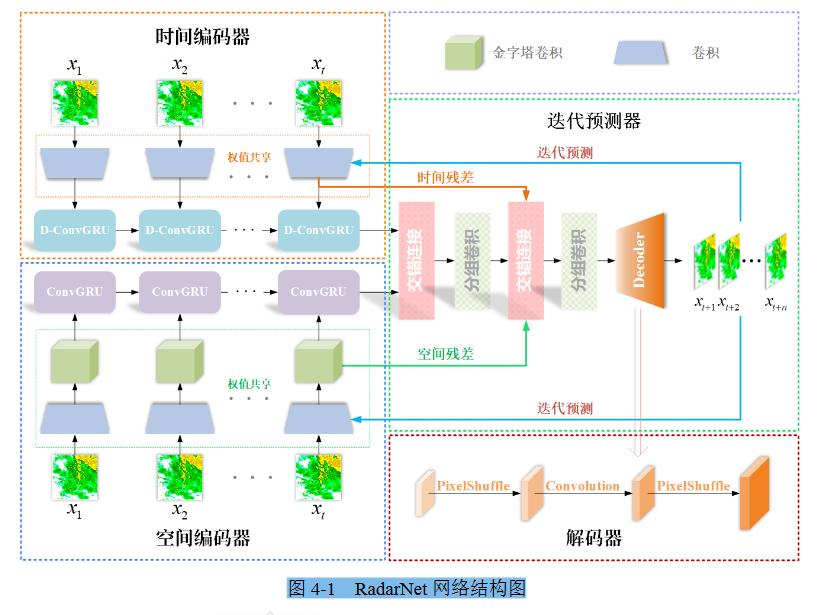
MMINR: Multi-frame-to-Multi-frame Inference with Noise Resistance for Precipitation Nowcasting with Radar
MMINR:抗噪多帧到多帧推理,用于雷达降水预报
摘要
基于雷达回波图的降水预报在气象研究中至关重要。最近,基于卷积 RNN 的方法占据了这一领域的主导地位,但它们无法通过并行计算解决,导致推理时间更长。基于 FCN 的方法采用多帧到单帧推理 (MSI) 策略来避免这个问题。它们再次反馈到模型中,预测下一个时间步,从而在预测阶段获得多帧即时广播结果,这将导致预测误差的累积。此外,由于降水噪声的不可预测性,它是造成高预测误差的关键因素。为了解决这个问题,我们提出了一种新的具有抗噪性 (NR) 的多帧到多帧推理 (MMI) 模型 MMINR。它避免了并行计算中的误差积累,并抵抗了降水噪声的负面影响。NR 包含噪音消除模块 (NDM) 和语义恢复模块 (SRM)。NDM 有意去除噪声简单而有效,SRM 补充了特征的语义信息,以缓解 NDM 错误丢失语义信息的问题。实验结果表明,与其他 SOTA 相比,MMINR 可以获得竞争性分数。烧蚀实验表明,所提出的 NDM 和 SRM 可以解决上述问题。
一些不可预测的区域,如图所示,称为降水噪声,将增加误差积累。两个连续雷达帧之间的间隔通常长达几分钟,由于大气系统的极端复杂性,这些噪声的突然消失或出现几乎是不可预测的。
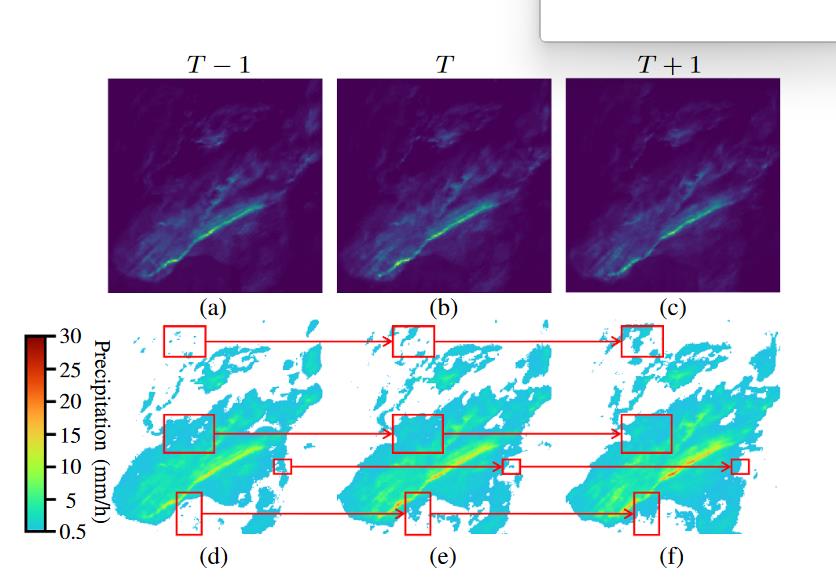
因此,我们期望一个能够满足以下特性的模型来解决上述问题:
(a) 该模型可以通过并行计算求解。
(b) 该模型具有简单的体系结构。
(c) 该模型可以避免预测误差的积�累。
(d) 该模型可以处理降水噪声。
MIMINR 基于雷达回波图的抗噪多帧到多帧降水预报推理模型。
使用多帧输入,通过在最后一个卷积层中添加输出通道,一次生成多帧输出,以减少预测误差的累积,而不是沿用以前基于 FCN 模型的循环或单帧推理模型。
抗噪性 (NR) 包括噪声抑制模块 (NDM) 和语义恢复模块 (SRM)。NDM 通过逐层减少信道数来减少噪声向网络深层的传播。为了补偿 NDM 在丢失噪声的同时丢失的语义信息,提出 SRM 来增强解码器中的语义特征融合。
-
提出了一种新的多帧到多帧推理模型 MMINR,用于降水预报。它在最后一个卷积层有多个输出通道。与其他基于 FCN 的方法相比,它显著减少了预测误差的累积。
-
提出了一种新的抗噪策略,该策略在编码器中包含噪声丢失模块 (NDM),在解码器中包含语义恢复模块 (SRM)。NDM 通过逐层减少特征通道来丢弃降水噪声,而 SRM 通过融合先前和当前时间步长的语义信息来增强语义信息的挖掘。
-
消融研究的实验结果以及与基于 ConvRNN 的 SOTA 和基于 FCN 的 SOTAs 的比较表明,MMINR 获得了竞争分数。提出的 NDM 和 SRM 可以减轻降水噪声的影响,增强语义信息的提取。
MIMINR 的流程图
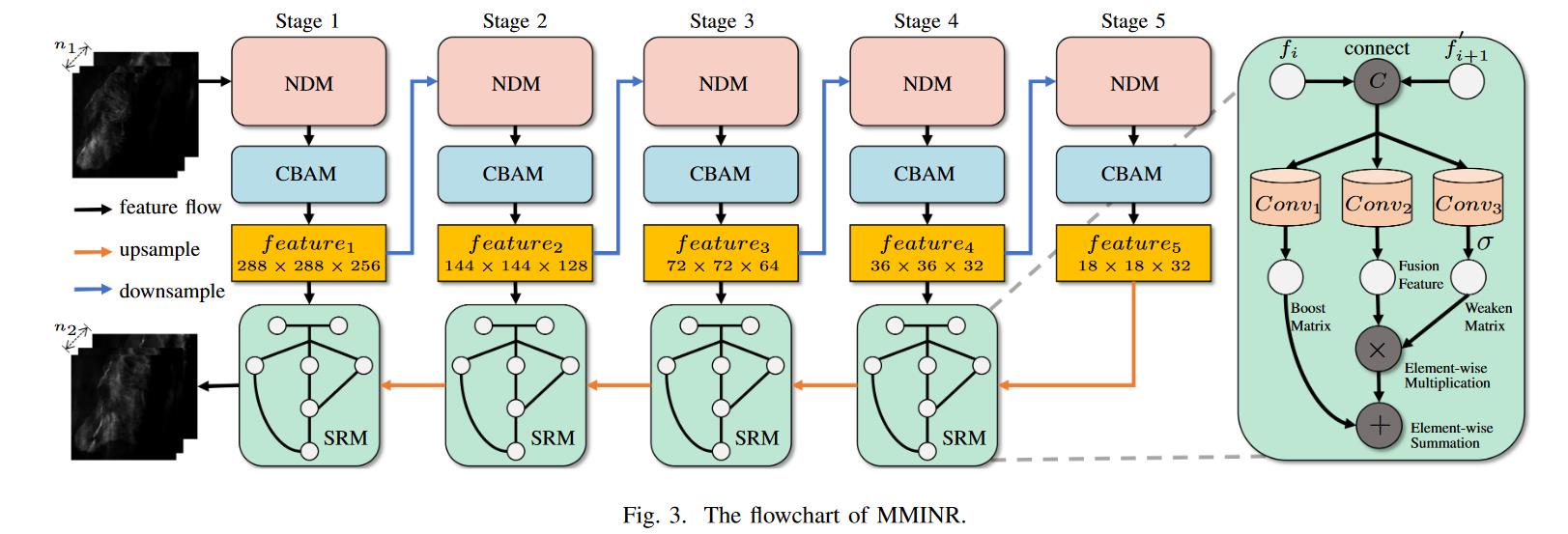
从计算机视觉的角度,降水量预报问题定义为一个逐序列问题,输入数据喝预测结果是雷达回波图序列。X 和 Y 分别表示输入数据和预测结果。Y 的 len 和 X 相同。
噪声去除
连续两个雷达帧之间的时间间隔通常长达几分钟,因此一些雨区在帧之间会突然消失或出现变形。这些区域几乎不可以预测,应该视为降水噪音。这些噪声将传到更深的层,导致基于经典的 FCN 模型的性能下降。为解决这个问题,设计了一种新的抗噪策略,它由编码器中的 NDM 和解码器的 SRM 组成
-
NDM
去除回波图上的噪声,构建了五个处理阶段,每个处理阶段包含一个 NDM。NDM 使用卷积运算从输入数据中提取特征 (进而减少网络更深的特征通道的数量)。
更具体地说,第一个 NDM 从原始地雷达图像提取特征,并生成 256 个通道地浅层特征。其他 NDM 进一步挖掘输入特征,并将特征通道数减少 1/2,以降低降水噪声。
同时加入了 attension 模块 (Convolutional Block Attention Module [CBAM]),在每一步 NDM 之后进一步挖掘语义特征。
CBAM 可以表示为:
-
SRM
尽管 CBAM 增强了模型的语义信息挖掘的能力,但前一阶段丢弃的语义特征仍然无法转到当前阶段。为了解决这个问题。设计了一个语义恢复模块 (SRM) 来检索丢失的语义信息。SRM 的结构如上图。
SRM 接收两个输入数据,即当前阶段的特征 (f_i) 和上采样后的后一阶段特征 ()。
由于 f_i 包含 丢失的语义信息,SRM 自适应地从 f_i 捕获语义特征信息 已补充
-
通过连接操作将它们组合在一起。
-
然后用三个不同地卷积模块提取三个特征,分别记录为增强矩阵、融合特征和减弱矩阵。
削弱矩阵中的所有值都在 0-1 之间,由一个 S 型函数表示。它与融合特征相乘,以减少一些被认为不需要的特征值,增强矩阵添加了削弱的融合特征,以增强需要增强的值。
-
评分方法
为了进行综合评估,我们采用了两个二进制度量和两个非二进制度量。二进制度量将预测结果二值化,并关注不同降水强度预测的预测结果的准确性。非二进制度量集中于预测结果和 GT 的相似性,关键成功指数 (CSI) 和 HSS 评分是二进制指标。CSI 测量正确预测的观察到和 (或) 预测事件的分数,HSS 测量命中概率于发出错误警报概率的比率。除相关性以外,所有二进制评估指标均基于真阴性 (TN)、假阳性 (FP)、伪阴性 (FN) 和真阳性 (hits)。
对于二元降雨图,将 0.5mm/h、2mm/h、5mm/h、10mm/h 定义为特定阈值。由于降水数据集的极度不平衡,建议 banlance-MSE(B-MSE) 和 banlance-MAE,根据降雨强度为降雨区域分配权重,以减轻数据不平衡的负面影响。
Effective Training Strategies for Deep-learning-based Precipitation Nowcasting and Estimation
基于深度学习的降水预报和估计的有效训练策略
摘要
深度学习已成功应用于降水预报。在这项工作中,提出了一个预训练方案和一个新的损失函数,用于改进基于深度学习的即时广播。首先,我们采用广泛使用的深度学习模型 U-Net 来解决这里感兴趣的两个问题:降水量预报和根据雷达图像估计降水量。将前者表述位具有三个降水间隔的分类问题,而后者表述为回归问题。对于这些任务,建议对模型进行预训练,以便在不久的 jangle 预测雷达图像,而不需要地面的实况降水,还建议使用新的损失函数进行微调,以缓解不平衡问题,以缓解类别不平衡问题。
值得强调的是,我们的预培训方案和新的损失函数在 5 小时的提前期内,将暴雨 (至少 10 毫米/小时)预报的临界成功指数(CSI)分别提高了 95.7% 和 43.6%。我们还证明,与传统方法相比,对于小降雨量 (1 至 10 mm/hr),我们的方法将降雨量估计误差降低了10.7%。最后,我们报告了我们的方法对不同分辨率的敏感性,并对四个暴雨案例进行了详细分析。
一种流行的传统降水预报方法是光流法。光流是一种计算图像强度运动的方法,已广泛用于基于雷达反射率的降水临近预报。具体来说,它通过估计速度场来推断雷达反射率。尽管其计算复杂度较低,但光流在降水临近预报方面通常显示出比 NWP 更好的预测性能 [11, 12]。此外,光流已与 NWP 相结合,以实现两种方法的优势 [13, 14]。然而,模��型参数很难确定,特别是因为光流的两个步骤 (即速度场估计和雷达外推) 是分开执行的。
为了充分发挥深度神经网络的能力,模型架构和使用的训练方法都很重要。例如,要将深度学习模型应用于降水临近预报,应考虑类别不平衡问题。也就是说,如果与非降水情况和小雨情况相比,暴雨情况的数量相对较少,则分类器很容易偏向具有大量示例的大多数类,从而导致深度学习模型对强降雨的预测性能较差,必须精确预测。用高度不平衡的数据缓解了密集对象检测中的这个问题,提出了焦点损失,它允许正在快速训练的模型通过在训练期间降低简单示例的重要性来专注于具有挑战性的示例。为了获得更高的 F1 分数,该分数被广泛用于在类不平衡时评估分类器,提出了在二元交叉熵之外使用骰子损失,并且设计了一个可微的损失函数接近 F1 分数,经验证明它与 F1 分数高度相关。
预训练深度学习模型最近成为计算机视觉和图像处理的主要范式。预训练深度学习模型是指为相关任务训练模型,这些任务通常使用较大的数据进行监督,或者在不需要稀缺标签的情况下无监督,以帮助模型学习对目标任务有用的参数。
方法
将降水分为三类:10mm/h、1-10mm/h、< 1mm/h。
微调阶段
对于降水临近预报,是最小化两者之间的差异
(a) 对应区域有气象站的每个像素在重 (10mm/h)、轻 (1-10mm/h) 和< 1mm/h 三个类�别上的输出概率分布。
(b) 从气象站测量的降水中获得的地面真实类别分布。
交叉熵 (CE) 损失被广泛用于测量这种差异。
现在尝试使用 临界成功指数 (CSI) 来缓解类不平衡问题。
| 预测 晴 | 预测 雨 | |
|---|---|---|
| 真实 晴 | correctnegatives | falsealarms(误警) |
| 真实 雨 | misses(漏报) | hits(击中) |
CSI 分数不能直接用作损失函数的一部分,因为它不可微分。
AA-TransUNet: Attention Augmented TransUNet For Nowcasting Tasks
摘要
近年来,基于数据驱动的建模方法在许多具有挑战性的气象应用 (包括天气要素预测) 中得到了广泛关注。本文介绍一种新的基于 TransUNet 的数据驱动的降水预报模型。TransUNet 模型结合 Transformer 和 U-Net 模型,此前已成功应用于医学分割任务。这里 TransU-Net 模型被用作核心模型,并进一步配备了卷积块注意模块 (CBAM) 和深度可分离卷积 (DSC)。建议的注意力增强 TransUNet(AATransUNet) 模型是在两个不同的数据集上,该模型都优于其他被检验模型。此外。还提供了拟建 AA TransUNet 的不确定性分析,以进一步了解其预测。
UNet 模型介绍
该模型使用具有跳跃连接结构的经典编码器 (下采样) 和解码器 (上采样)。UNet 最初用于医学图像分割,但它逐渐开始在许多其他计算机视觉任务中发挥作用。受 UNet 模型成功的启发,文献中还在开发了其他几种架构,这些架构继续坚持 UNet 的核心概念,尽管加入了新的模块或其他技术。
Transformer 架构
这种带有注意力机制的序列到序列结构被设计用于处理输入数据。在计算机视觉任务中,有 Vision Transformer 模型,该模型将图像分成固定大小�的小块,线性嵌入每个小块,添加位置嵌入,并将生成的矢量序列输入标准 Transformer 编码器。
尽管基于 Transformer 的模型在计算机视觉领域具有巨大潜力,但它也面临一些重大挑战,例如对数据的高需求。同样,在图像分割领域一直占据主导地位的 UNet 结构也存在一些局限性,例如无法捕获长期依赖性。因此,将变压器与 UNet 模型相结合成为一个新的研究方向。
这里,TransUNet 被用作核心模型,并进一步配备了卷积块注意模块 (CBAM) 和深度可分离卷积 (DSC)。
在减少可训练参数的同时不会降低模型的准确性。
这里我们使用的数据集是降水图数据集和云覆盖数据集。对于降雨量图数据集,模型输入包括从制图雷达收集的 60 分钟降雨量图,模型输出是预测未来 30 分钟降雨量图的另一序列。
我们还对云覆盖数据集进行了相关实验,以证明该模型的适用性。
相关工作
施博士提出了卷积 LSTM(Convolutional LSTM) 模型,该模型能够更好地捕获数据的潜在时空相关性,并始终优于普通 LSTM。继续沿着 ConvLSTM 的研究方向,提出了 Convcast,一种基于嵌入式卷积 LSTM 的体系结构。介绍了不同的 CNN 架构,包括一维、二维和三维卷积,以准确预测未来 6 到 12 小时的风速。UNet 架构用于降水量预报。SmaAt-UNet 模型是 UNet 模型的扩展,它在不影响性能的情况下大大减少了 UNet 参数。作者通过为 UNet 模型配备不对称并行卷积以及 Atrous Spatial Pyramid Pooling(ASPP) 模块,介绍了 Broad-UNet。
卷积块注意模块 (CBAM) 和深度可分离卷积 (DSC)
CBAM 是前馈卷积神经网络的一个轻量级通用注意模型。给定一个中间特征图,CBAM 依次推断出两个维度的注意图 (通道注意力模块和空间注意力模块)。深度卷积 (DW) 和点卷积 (PW) 统称为深度可分离卷积。这种结构类似于常规卷积运算,可用于提取特征,同时其参数大小大大小于标准卷积运算。
方法
该模型如图所示,用于降水量预测任务。我们将由通道注意模块 (CAM) 和空间注意模块 (SAM) 组成的 CBAM 集成到 TransUNet 模型的编码器和解码器路径。特别是,在编码器路径中,CBAM 被合并到混合 CNN Transformer 层的 CNN 部分,在解码器路径中,它被放置在所有卷积层之后 (见图 1)。这使得模型能够同时进行通道和空间关注,因此可以更好地探索特征的通道间和空间间关系。此外,TransUNet 解码器的原始卷积被 DSC 取代,旨在减小其参数数量。在表一中,我们比较了 TransUNet 和 AA TransUNet 型号解码器的参数数量。
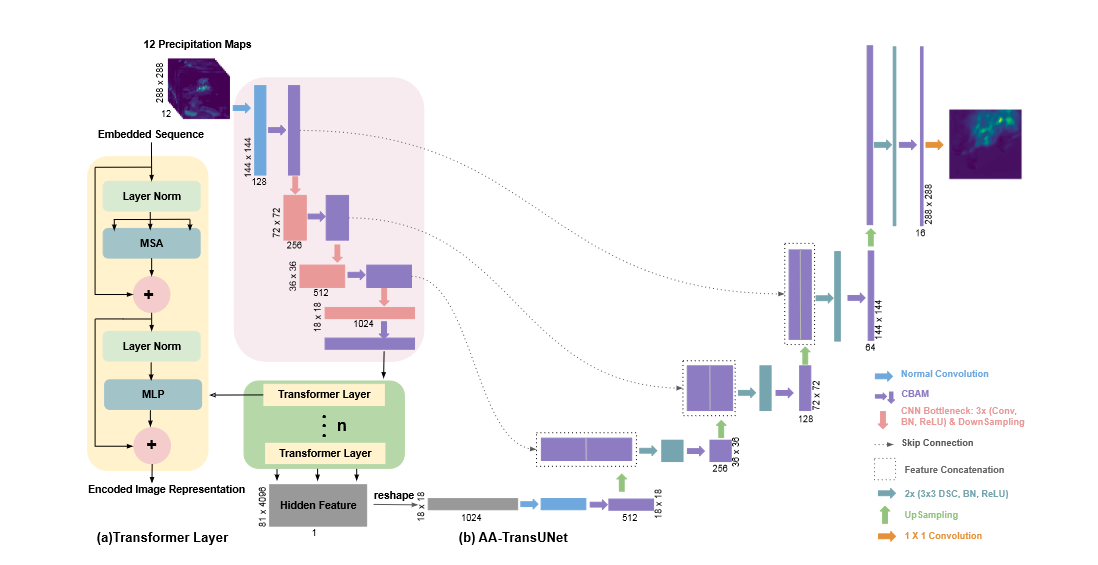

与 TransUNet 类似,AATransUNet 模型的编码器是基于 Transformer 模型,通常用于处理序列数据。因此,当将其用作编码器时,需要首先执行图像序列化步骤,以将 3D 图像转换为 2D 补丁。然后将获得的补丁馈送到 Transformer 层,该层由 Multihead Self Attention(MSA) 层和 Multi layer Perceptron(MLP) 块组成 (每个 MSA 和 MLP 都通过层规范化门)。同时,没有使用纯 Transformer 作为编码器,而是使用 CNN Transformer 来利用解码路径中的中高分辨率 CNN 特征映射,提高模型性能。
如上图所示,AA TransUNet 解码器中使用了四种操作:上采样 (绿色箭头)、特征串联 (虚线矩形)、双卷积 (青色箭头),最后是 CBAM(紫色箭头)。模型的最后一层是 1 x 1 卷积 (橙色箭头),它生成一个表示预测结果的单个特征图。
TransUNet 和 AA TransUNet 中 Transformer 层的数量都设置为 1,因为经验证明这是最佳选择。
Annealing Genetic GAN for Minority Oversampling
摘要
生成对抗网络 (GAN) 具有给定大量训练数据样本的情况下再现数据分布的能力,因此在解决班级不平衡问题方面显示出一些潜力。然而,一个或多个类的稀缺样本仍然对 GAN 学习少数类的准确分布提出了很大的挑战。本文,提出了一种退火遗传 GAN(AGGAN) 方法,该方法旨在仅使用有限的数据样本来复制于少数类分布最接近的分布。AGGAN 将 GAN 的训练更新为一个包含模拟退火机制的进化过程。特别是,生成器不同的训练策略来生成多个后代并保留最好的。然后,我们在模拟退火中使用 Metropolis 准则来决定是否应该更新生成器的最佳子代。由于大都会标准允许一定的机会接受较差的解决方案,它使 AGGAN 偏离了局部最优。通过对多个不平衡图像数据集的理论分析和实验研究,我们证明了所提出的训练策略能够使 AGGAN 从稀缺样本中再现少数类的分布,并为类不平衡问题提出了一个有效且稳健的解决方案。
AGGAN 策略
- 将模拟退火遗传算法融入到 AGGAN 的训练过程中,以避免局部最优捕获。
- 通过理论分析,发现模拟退火遗传算法能够使 AGGAN 重现最接近少数类的分布。
- 从而解决不平衡的问题。
AGGAN 旨在从少数群体中学习精确分布。首先,AGGAN 使用不同的对抗性学习目标来提高生成器的性能。其次 AGGAN 将模拟退火机制融入训练,使模型能够收敛到最接近少数类的分布。特别是,替代 GAN 的正常培训。
AGGAN 作为一个进化过程进行训练,鉴别器 D 作为环境,生成器 G 作为个体。个体的每次迭代分为两个步骤,包括 (step 1)生成最适合的子代,(step 2)更新生成器,如下图所示。
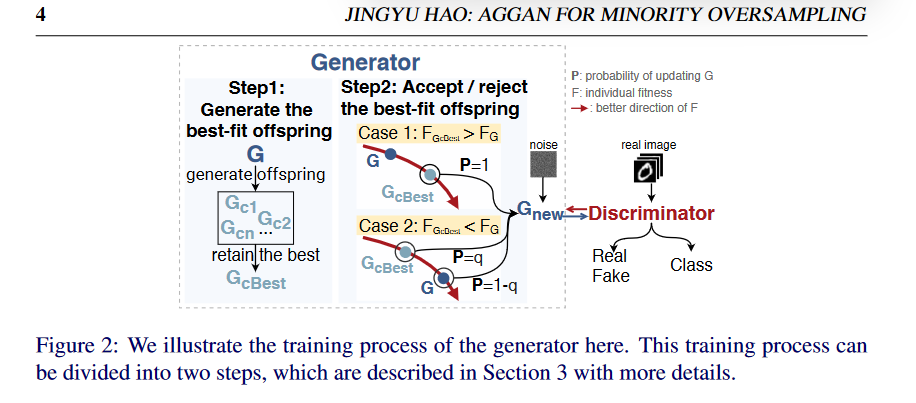
生成最佳拟合后代
在每次迭代中,G 通过不同的对抗性学习目标产生不同的后代 Gc。每个 Gc 代表发电机网络参数空间中的一个解决方案,根据生成样本的多样性和质量评估后代 Gc 的个体适应度。然后保留最合适的子代 Gcbest,而排除其他子代。生成最合适的后代 GCbest 的过程反映了 GA 中的“适者生存”的概念。使用不同的对抗目标的策略克服了使用固定目标的限制,有助于最终学习的生成器实现更好的性能。
更新生成器
本文使用 SA 机制来更新生成器。
如果 GcBest 的个体适应度高于 G,则 GcBest 将更新为 Gnew,概率为 1。
如果 GcBest 的个体适应度低于前一代 G,则 GcBest 将更新为 G,概率为 P。
概率是 P 根据当前温度 Tc 和两个个体适应度之间的差来确定的。温度 Tc 从退火系数的初始温度 T 开始逐渐降低。在这样做的过程中,在一个更坏的方向上以降低的概率更新 G 可以使 AGGAN 渐近收敛到全局最优。
最后更新个体后,环境 (即鉴别器)D 的更新,AGGAN 的训练循环开始下一个进化迭代。随着训练进行,G 生成的数据逐渐接近真实分布,这有助于 D 不断提高分类精度。
理论分析
本文将 GAN 的训练视为一个组合优化问题。我们把这个组合优化问题看作一对 (G,f) 其中 G 是生成器 g 的解空间的有限集,f 是目标函数。目的是找到一个全局最优值来优化最小化 f。值得注意的是,G 的有限性意味着 f 在 G 上至少有一个最小值。
生成最适合的子代 Fgen
首先,使用选择函数从**[g,gb]**中找到父代 g,然后 g 在产生函数下生成后代 gc。最后,我们从单个适应度函数中保留最合适的子代 gcbest
公式概述为:
由于选择函数、生成函数和个体适应度函数的参数不依赖于迭代次数, 将遵循相同的分布,迭代次数不同。
更新生成器 Fupd
更新生成器的过程中使用 SA 的机制。公式概述为下:
注 是 g 和 gcbest 的个体适应度之间的差异, 是 0 和 1 之间的随机变量,T 表示 AGGAN 的温度参数。
结合 和 得到 F,用于表示生成器的迭代过程
Autonormously and SImultaneously Refining Deep Neural Network Parameters by a Bi-Generative Adversaril Network Aided Genetic Algorithm
用遗传算法辅助双生成对抗网络,自动、同时优化深层神经网络参数。
摘要
参数的选择和网络结构的设计是影响深度神经网络性能的重要因素。遗传算法 (GA) 以前曾用于确定网络参数。然而 GA 对一组离散的预定义候选者执行有限搜索,通常不能生成看不见的配置。在本文中为了探索过渡到开发,提出了一种新的系统化方法,该方法利用双生成�对抗网络 (bi-GAN) 辅助的遗传算法,自动同时优化任何深度神经网络的多个参数。提出的 Bi-GAN 允许从大范围的值中自主开发和选择全连接层的神经元的数量和卷积层的卷积核的数量。我们提出的 Bi-GAN 涉及两个生成器,两个不同的模型通过 GAN 的策略在 GA 进化过程中相互竞争核改进,以优化网络。我们提出的方法可用于自动细化卷积层核稠密层的数量、核的数量和大小以及稠密层神经元的数量;选择激活函数的类型;并决定是否使用丢包和批量归一化,以提高不同深度神经网络结构的精度。在不损失通用性的情况下,使用 ModelNet 数据库对所提方法进行了测试,并与 3d Shapenets 和两种仅使用 GA 的方法进行了比较。结果表明,该方法能够同时成功地优化多个神经网络参数,即使在较浅的网络中也能达到较高的精度。
本文提出了一种新颖而系统的方法,它采用了一种改进的生成对抗网络。称为 Bi-GAN,并结合遗传算法 (GA)。该方法可以自动细化卷积层的数量、滤波器的数量和大小、稠密层的数量和神经元的数量;决定是否使用批量归一化和最大池化;选择激活函数的类型;并决定是否使用 Dropout。
Bi-GAN network
提出了新的、改进的生成性对抗网络 (GAN),称为 Bi-GAN,用于寻找具有较大取值范围的最优网络参数。
用于细化不同神经网络参数的 Bi-GAN 网络如图所示:它由生成部分、评估部分和鉴别器组成。与传统的 GAN 相比,有两个生成器 (G1 和 G2)、两个评估器 (E1 和 E2) 和一个鉴别器 (D)。两个生成器的输入为高斯噪声,另一方面,评估人员的输入是训练数据。
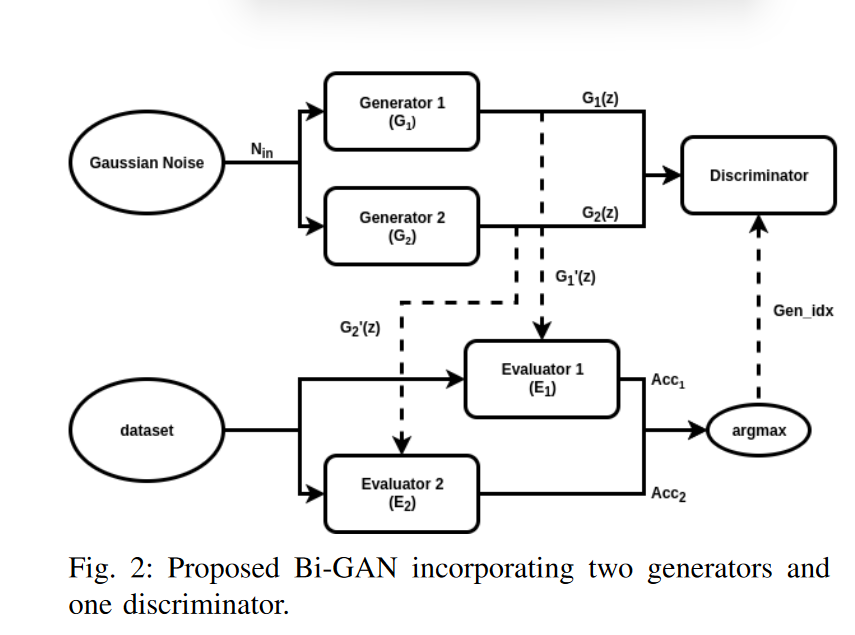
生成器 G1 和 G2 具有相同的网络结构。根据输入噪声,G1 和 G2 生成输入网络参数 G1(z) 和 G2(z)。
E1 和 E2 具有神经网络结构,其参数正在优化或细化。它们计算训练数据的分类精度 x。E_i(x,G_i(z)) , ii in [1,2] 表示使用参数 G_i(z) 时评估器 获得的分类精度。 产生更高精度的生成器 标记为 更精确 的生成器 另一个生成器标记为 其中 。
将鉴别器 D 定义为一个网络,用于较好和较差的生成器之间的二进制分类。
和。鉴别器提供梯度来训练性能较差的生成器。
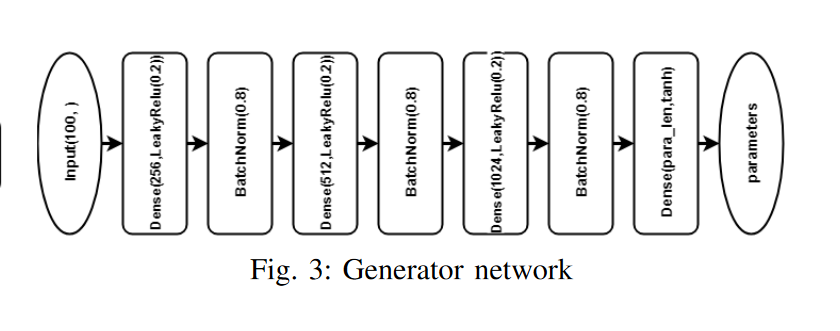
- 生成部分:两个生成器 G1 和 G2 具有相同的神经网络结构。如上图 (3) 所示,他们的输入是高斯噪声矢量 z。输出是 和。生成器由具有泄露相关激活的完全连接层组成。在输出层,采用 tanh,因此
然后, 的 (-1,1) 到
公式:
在上式中 和 是预设的最大值和最小值,它们是根据某个参数可以采用的值 (根据经验定义的),因此细化参数的值只能在 和 之间变化。例如,对于完全连接层的神经元数量, 和 分别为 4000 和 10.然后使用重新缩放的值 和 作为评估器网络的参数。$$G_i(z)$的长度由优化的网络参数的数量决定,并在生成器网络的最后一个完全连接层设置。
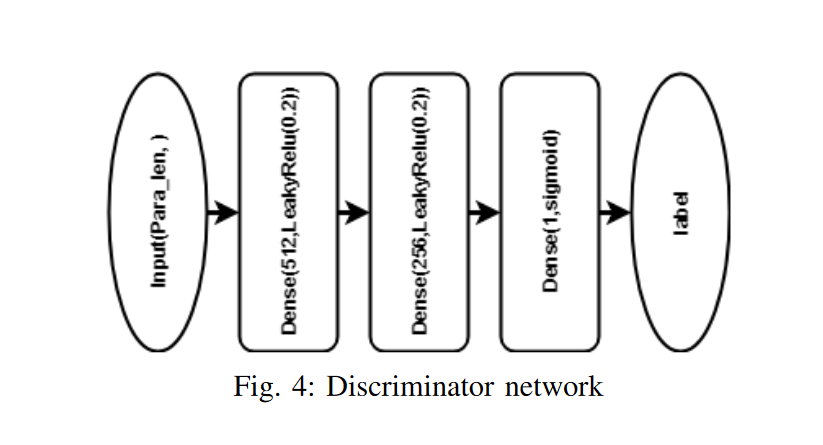
鉴别器对生成器进行训练/改进,鉴别器是一个二进制分类器,用于将结果与生成器输出 和 区分开来。标签“a”和“b”分别表示具有较高精度和较低精度结果的生成器。性能较差且标记为“b”的生�成器通过来自鉴别器的随机梯度下降 (SGD) 来训练。以最小化 :
m is the number of epochs
当连续两次迭代的 等于 ,的权重将重新初始化 为默认随机值。这一步的目的是防止优化在局部最大值,也防止消失 tanh 梯度问题。
- 评估部分:如上所述,所提方法的优点之一是可以用于优化不同深度神经网络结构的参数。换言之,评估网络与参数��正在优化或细化的神经网络具有相同的结构。
评估器网络是使用生成器提供的参数 和 构建的。训练数据 用于评估这些网络模型。我们采用提前停止标准。更具体地说,如果在 c 个 epochs 里没有改进,则停止训练。
然后我们获得
设 a 为 ii 的值,以获得更高的精度, 然后使用“a”作为鉴别器的基本真值标签,它用更好的参数标记生成器,并训练较差的生成器。
鉴别器:我们将鉴别器 D 定义为一个网络 (如图 4 所示),其输出为标量 softmax 输出,用于更好的生成器和更差的生成器之间的二进制分类。 和 被输入鉴别器 D,并且关于哪一个是更好的生成器的基本真相标签来自评估器。设 D(G(z)) 表示 G(z") 来自更精确的生成器 Ga 而不是 Gb 的概率。我们训练 D 以最大化为两个生成器的输出 G1(z) 和 G2(z) 分配正确标签的概率。此外,我们同时训练较差生成器 (Gb) ,以最小化日志 (1- D (Gb(z)))。整个过程可以表示为:
伪代码:

遗传算法
在每个 GA 进化中,Bi-GAN 用于设置/优化卷积层的滤波器数和密集层的神经元数。然后,对网络模型进行训练和评估,以获得其准确度分数。根据准确度得分,应用遗传算法。
- 初始种群:第一代网络 是随机生成的其中
其中是模型的数量。这是通过从可能的选择中随机选择 (2) 和 (3) 中卷积核稠密参数的值来实现。
2)Bi-GAN 优化:Bi-GAN 用于更新 网络模型的完全连接层的神经元数量核卷积层的滤波器数量。
-
评估:在完全连接层的神经元数量和卷积层的滤波器数量由 Bi-GAN 确定后,每个生成的网络模型 将通过适应度函数 进行评估,这是对每个模型准确性的度量。性能更好的模型将具有更高的值。因此, 将保持体能得分 ,其中 。
-
选择:在选择部分,从排序的 (E) 中选择 t-many 排名靠前的模型,从其余网络模型中随机选择 r-many 模型。然后,丢弃 d-many 模型,以防止过拟合和陷入局部最优。其余选定的模型是父模型 (P),将用于为下一代创建新模型。
-
交叉和变异:交叉应用于从父节点生成 子网络模型。父池的选择如下:我们将计数器 与每��个父池 P 相关联,并将其初始化为零,而不是总是从父池中随机选择两个父池。
每次使用父级进行交叉时,此计数器递增 1。首先,从 t+r-d many 父母中随机选择俩个父母。通过交叉从父节点生成一个新的“子节点”网络,父节点的计数器递增 1。
然后,从父池中随机选择两个计数器仍然为 0 的 父池。通过交叉从它们生成另一个网络,父节点的计数器递增。如果只剩下一个计数器为 0 的网络模型,并且子模型的数量仍然小于 ,则选择此模型作为父模型之一,并从计数器值为 1 的其余模型中随机选择另一个父模型。如果计数器等于 0 的父级已经不存在,并且子级的数量仍然小于,则随机选取计数器为 1 的两个父级,并且在交叉后,它们的计数器将增加到两个。
重复此过程,直到子模型的数量达到。
父模型 a 和 b 之间的交叉如图 5 所示。前两个整数 (ID1 和 ID2) 分别在 1 和 C 以及 1 和 D 之间随机选取。然后设置子网络的参数。以便
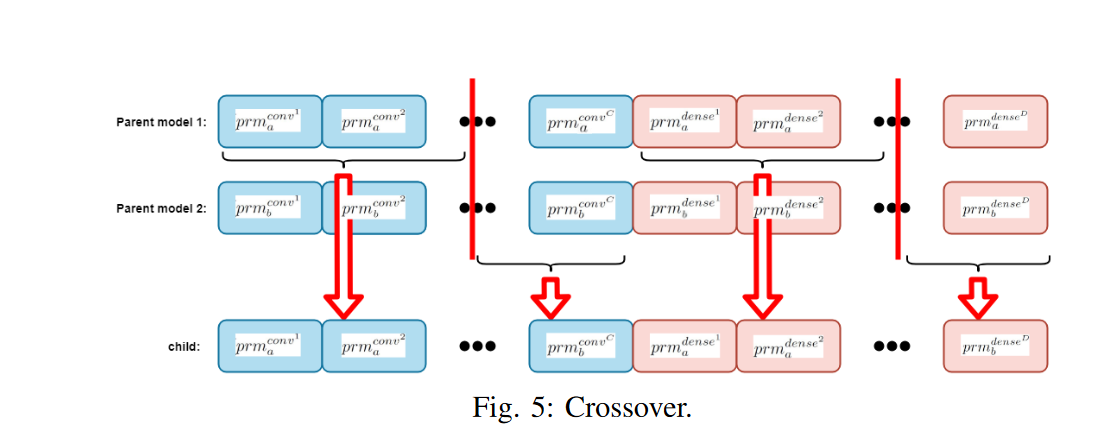
通过交叉获得所有 多个子网络后随机选择 20% 的种群进行变异。如 (2) 和 (3) 所示,有五种不同的卷积层参数和四种不同的稠密层参数。
使用提出的 Bi-GAN 等更新种群中的每个网络模型的神经元数量和过滤器数量。重复整个过程。
伪代码:

Rainformer:Features EXtraction Balanced Network for Radar-Based Precipitation Nowcasting
Rainformer:基于雷达的现代降水特征提取平衡网络
摘要
降水预报是自然灾害研究的基本挑战之一。高强度降水,特别是暴雨,将导致人民财产的巨大损失,现有的方法通常利用卷积运算来提取降雨特征,并增加网络深度来扩展接收场以获得伪全局特征。虽然该方案简单,但只能提取局部的降雨特征,导致对高强度的降水不敏感。
本文提出了一种新的降水预报框架 Rainformer,其中提出两个实用组件:全局特征提取单元 和 门融合单元 (GFU) 。前者依靠基于窗口的多头部自我注意 (W-MSA) 机制提供强大的全局特征学习能力,而后者提供局部和全局特征的均衡融合。Rainformer 具有一种简单而高效的结构,可以显著提高降水量预测的准确性,特别是在高强度降水的情况下。它为实际应用提供了潜在的解决方案。实验结果表明,Rainformer 在基准数据库上的表现优于七种最先进的方法并为高强度降水预测任务提供了更多见解。
Rainformer 介绍
Rainformer 主要由特征提取平衡模块 (FEBM) 构成,该模块包含一个局部特征提取单元、一个全局特征提取单元和一个门融合单元 (GFU)。本地特征提取单元重点是提取中低降水强度信息。全局特征提取单元基于窗口的多头部自我注意 (W-MSA)。
此外由于全局特征和本地特征之间的自然不平衡,我们建议 GFU 以平衡的方式融合全局和本地特征。更具体地说。GFU 通过选通机制为局部和全局特征生成两个遗忘矩阵。它减少了特征之间地数值差异,并使其更加容易融合。此外,由于我们不使用递归单元,梯度爆炸问题大大减轻。
Rainformer 模型
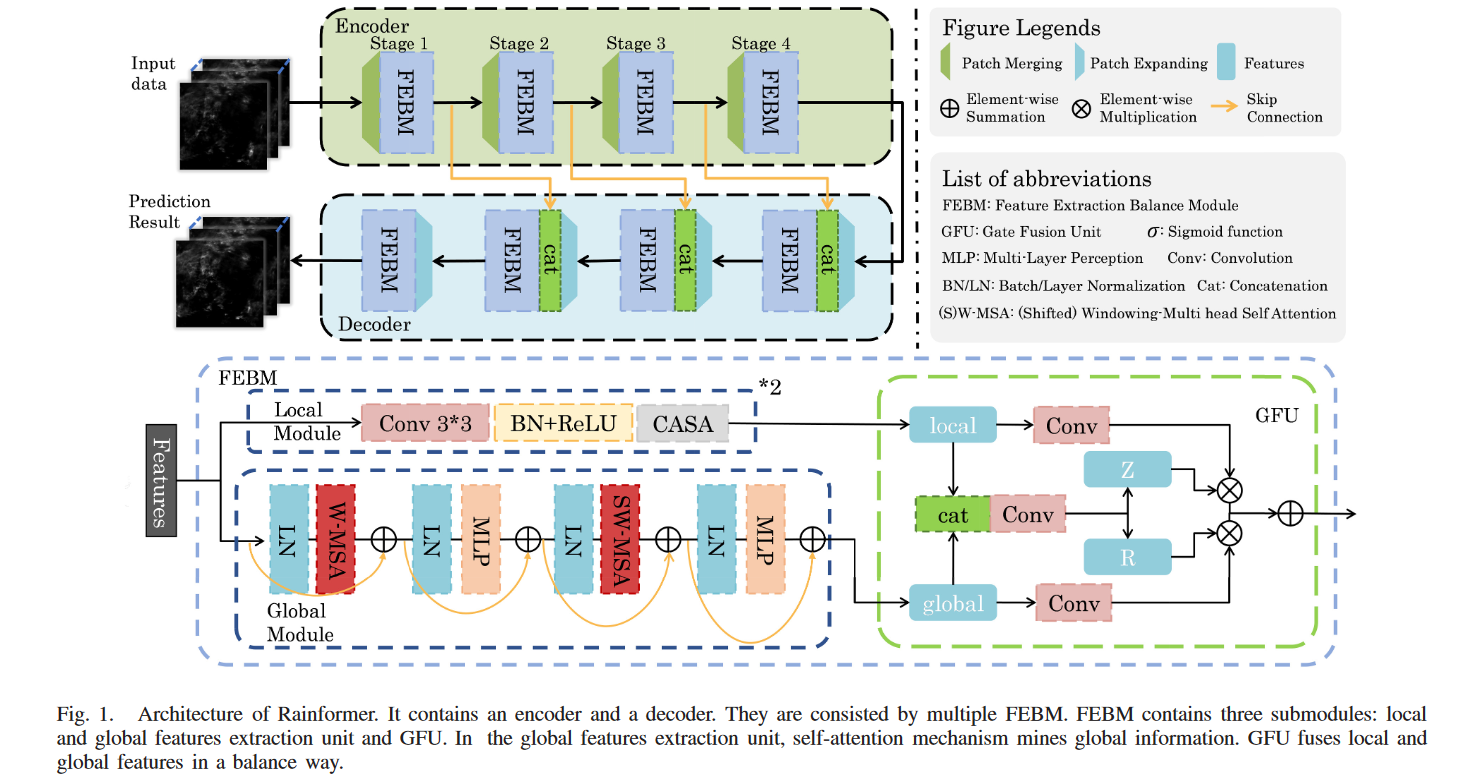
Rainformer 的总体框架如上图所示。Rainformer 由编码器 (绿色框) 和解码器 (蓝色框) 组成。它们都有四个阶段。当阶段越深,特征尺寸越小。编码器和解码器都包括 FEBM 增强了各个阶段的中低强度和高强度的降水特征。
在编码器中,每个阶段都包含一个下采样操作和一个 FEBM。可以假设 是 FEBM,编码器中的过程可以写成:
Fen_1 和 Fen_i 是 FEBM 输出的特征,X 是指输入数据,即雷达回波图的序列。i 表示阶段数,PM 表示下采样操作。
在解码器中,整个过程可以定义为:
其中 Fde_4 ,Fde_i ,Fde_1 是解码器中每个阶段的输出特征,PE 表示上采样操作。
解码器中的阶段 2 到 4 比编码器中的阶段多了一个级联操作。此操作允许来自编码器的特征不受阻碍地传输到解码器。
FEBM 模块 (Feature Extraction Balance Module 特征提取平衡模块)
基于自我注意的技术从输入的雷达回波图提取全局信息。FEBM 由一个局部特征提取单元、一个全局特征提取单元和一个 GFU 组成,用于平衡融合两个不同尺度的特征。
具体来说,我们的局部特征提取单元主要由卷积块和注意机�制组成。后者由通道注意和空间注意模块共同组成,即 CASA,也称为 CBAM。全局特征提取单元基于基于移位窗口的多头部自我注意 (SW-MSA) 和 W-MSA。全局特征提取单元将输入特征分为几个块。每个块都根据传统的自我注意算法计算注意图。然而,这些注意力图仍然是本地化的。然后移动每个块,使曾经独立的块具有重叠部分。在再次计算注意图之后,这些图覆盖了以前用于全局信息挖掘的不同局部区域。
Fate Fusion Unit(GFU) 门融合单元
如上图所示,整个计算过程可以表示为:
l 和 g 分别表示局部特征和全局特征。
Z 和 R 是对应于全局和局部特征的遗忘矩阵。Z 和 R 的值介于 0 和 1 之间,累死于选通机制 (gating mechanism)。它清空了需要遗忘或忽略的东西,保留了需要记住的东西。
GFU 通过上述的选通机制对局部和全局特征进行约束,极大地缓解了数值差异,避免了线性融合由于它们之间地显著差异而无法发挥作用地问题。我们使用这种选通算法,实现了特征融合地自动平衡。
VideoGPT : Video Generation using VQ-VAE and Transformers
摘要
VideoGPT:一种概念上简单的架构,用于将基于可能性的生成性建模扩展到自然视频。VideoGPT 使用 VQVAE,通过使用 3D 卷积核轴向自我注意来学习原始视频的下采样离散潜在表示。然后,使用一个简单的类 GPT 架构,使用时空位置编码对离散潜伏期进行自回归建模。尽管公式简单且易于训练,但我们的体系结构能够生成与最先进的 GAN 模型相竞争的样本,用于在 BAIR Robot 数据集上生成视频,并从 UCF-101 和 Tumbler GIF 数据集 (TGIF) 生成高清保真自然视频。
介绍
首先,我们在基于可能性的模型和对抗模型之间进行选择。基于可能性的模型便于培训,因为目标易于理解,易于在一系列批量大小中优化,并且易于评估。鉴于视频由于数据的性质已经提出了一个难以建模的挑战,我们认为基于可能性的模型在优化和评估方面的困难较小,因此我们可以将重点放在架构建模上。接下来,在基于可能性的模型中,我们选择自回归模型仅仅是因为它们对离散数据特别有效,在样本质量方面取得了更大的成功 (Ramesh 等人,2021),并利用了变压器架构中的最新创新,建立了完善的训练配方和建模架构。
下面,我们介绍选择前者的原因:自然图像和视频包含大量空间和时间冗余,因此我们每天都使用图像压缩工具,如 JPEG(Wallace,1992) 和视频编解码器,如 MPEG(Le Gall,1991)。通过学习高分辨率输入的去噪降采样编码,可以消除这些冗余。例如,跨空间和时间维度的 4 倍下采样会导致 64 倍下采样分辨率,因此强大的深度生成模型的计算将花费在这些更少且有用的位上。如 VQ-VAE(Van Den Oord et al.,2017) 所示,即使是有损解码器也可以转换潜在信号,以生成足够真实的样本。最近,该框架产生了高质量的文本到图像生成模型,如 DALL-E(Ramesh 等人,2021)。此外,由于降低了维数,在跨空间和时间而不是像素空间下采样的潜在空间中建模可以提高采样速度和计算要求。
模型结构
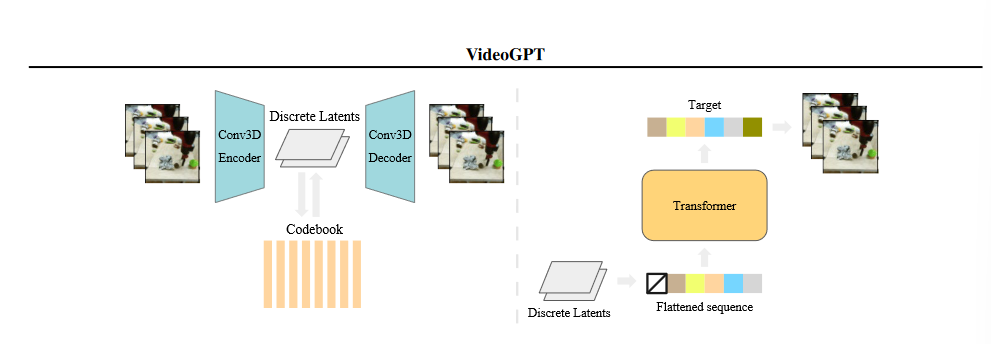
我们将训练流水线分为两个连续的阶段:训练 VQ-VAE(左) 和训练潜伏空间中的自回归变压器 (右)。第一阶段类似于最初的 VQ-VAE 培训程序。在第二阶段,VQ-VAE 将视频数据编码为潜在序列,作为先前模型的训练数据。为了进行推断,我们首先从先验信息中提取一个潜在序列,然后使用 VQ-VAE 将潜在序列解码为视频样本。
我们的结果强调如下:
1.在广泛基准化的 BAIR 机器人推送数据集 (Ebert 等人,2017) 上,VideoGPT 可以生成与现有方法 (如 TrIVD GAN(Luc 等人,2020)) 相竞争的真实样本,当用真实样本基准化时,FVD 为 103,当用重建基准化时 FVD*(Razavi 等人,2019) 为 94。
2.此外,VideoGPT 能够从复杂的自然视频数据集,如 UCF-101 和 Tumblr GIF 数据集
3.生成真实的样本。我们对 VideoGPT 中的几种架构设计选择进行了仔细的消融研究,包括轴向注意块的好处、VQ-VAE 潜伏空间的大小、码本的数量、,以及自回归先验的容量 (模型大小)。
4.VideoGPT 可以轻松适应动作条件视频�生成。我们展示了 BAIR 机器人推送数据集和 Vizdoom 模拟器的定性结果 (Kempka 等人,2016)。
GPT
GPT 和 Image GPT(Chen et al.,2020) 是一类自回归变换器,在建模离散数据 (如自然语言和高维图像) 方面取得了巨大成功。这些模型根据 p(x)=分解数据分布 p [ x ∏ d ii=1 p(xi | x< ii ) ],通过掩蔽自注意力机制,并通过最大似然优化。架构采用多头部自我关注模块,然后是点式 MLP 前馈模块,遵循标准设计 (Vaswani et al.,2017)。